Why do some recommendation systems feel eerily accurate while others miss the mark so badly they become background noise?
That gap matters because AI content recommendations are not just a neat trick.
They shape what people read next, how long they stay, and whether a brand feels useful or forgettable.
The hard part is that relevance is slippery.
A model can score engagement well and still miss context, timing, or intent, which is where personalized content marketing either clicks or falls flat.
That is why AI effectiveness in marketing needs a closer look than “Did it show more content?” A smart recommendation engine can raise attention, but the real test is whether it helps the right person find the right thing without feeling forced.
When it works, the experience feels natural.
A reader opens one article, then finds the next one at exactly the right moment, and the whole journey feels less like targeting and more like good judgment.
Quick Answer: AI-powered content recommendations rank what a specific visitor sees next by learning from behavior and content relationships, then updating what it surfaces as the session evolves. The key to “effectiveness” isn’t whether the module gets clicks—it’s whether the recommended next step matches the visitor’s intent. Measure that with relevance-focused, downstream outcomes (for example: conversion/lead rate, return visits, and time in the next content stage), not only impressions or click-through rate.
What AI-Powered Content Recommendations Actually Are
A reader lands on a site, glances at one article, and suddenly sees three others that feel oddly relevant.
That is not magic.
It is a recommendation system ranking content for that person based on signals like behavior, topic similarity, recency, and context.
AI content recommendations go a step beyond simple matching.
Basic personalization might show “people also read” items or swap headlines based on a saved rule.
AI models can weigh dozens of signals at once, then adjust as the reader keeps clicking, scrolling, or leaving.
The difference matters because content teams are not just trying to fill slots.
They want the next piece of content to feel like the natural next step, whether that means a deeper guide, a related product page, or a follow-up article that keeps the session alive.
That is where personalized content marketing gets more interesting.
A strong recommendation engine does not just mirror past behavior.
It predicts intent, spots patterns across similar readers, and ranks content by likely value for this exact visit.
In practice, that could mean showing a technical explainer to a reader who has already consumed beginner content, while another visitor sees a case study instead.
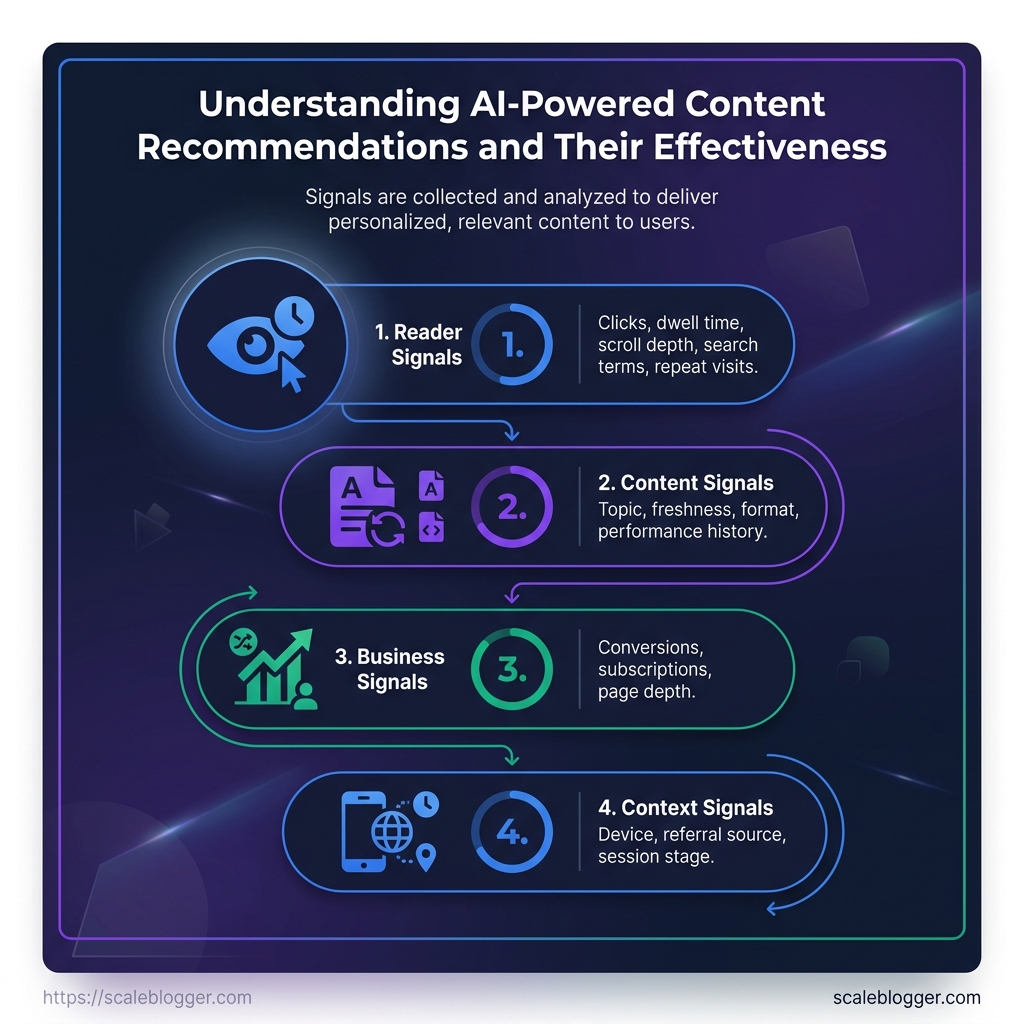
- Reader signals: clicks, dwell time, scroll depth, search terms, and repeat visits all shape the ranking.
- Content signals: topic, freshness, format, and performance history help the system judge fit.
- Business signals: conversions, subscriptions, or page depth can shift which items get priority.
- Context signals: device, referral source, and session stage often change what should surface first.
Teams care because recommendation quality affects more than traffic numbers.
Better matches usually improve engagement, reduce bounce, and help valuable pages get seen instead of buried.
Poor recommendations do the opposite.
They waste attention, flatten session depth, and make AI effectiveness in marketing look weaker than it really is.
A simple example makes it obvious.
If someone reads an article on content clustering, showing them another top-level intro is lazy.
Showing them a workflow guide, a checklist, or a pricing page is useful.
That small shift can change whether the visit ends in one page or five.
Good recommendations feel timely, not random.
They respect the reader’s intent, and that is where the real lift comes from.
How AI Recommendations Work Behind the Scenes
A recommendation engine is basically a fast reader with a very odd memory.
It watches patterns in clicks, scroll depth, time on page, and what people ignore just as closely as what they read.
That mix of signals matters more than raw traffic.
In personalized content marketing, a page with fewer visits can still win if it matches a user’s current intent better than the obvious choice.
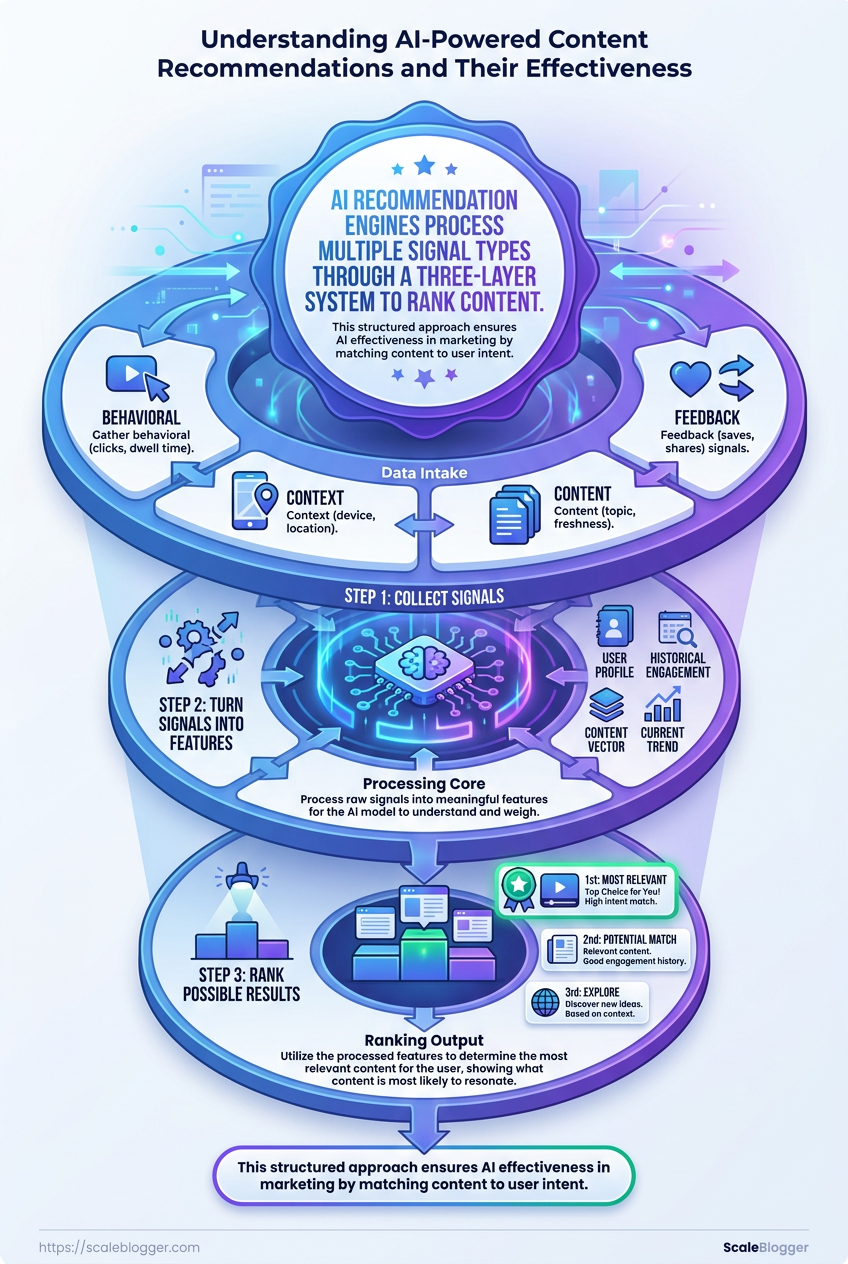
Behind the scenes, AI content recommendations usually follow three layers: collect signals, turn them into features, then rank possible results.
The ranking logic is rarely glamorous, but it is where AI effectiveness in marketing shows up or falls apart.
- Behavioral signals: Clicks, dwell time, repeat visits, searches, and exit patterns show what feels relevant in practice.
- Context signals: Device, location, referral source, time of day, and session history help the model guess what the user wants right now.
- Content signals: Topic, format, freshness, reading level, entity match, and semantic similarity tell the system what each piece is about.
- Feedback signals: Saves, shares, conversions, and skips teach the model which suggestions were useful and which were noise.
- Negative signals: Fast bounces, backtracking, and ignored recommendations are just as valuable. The model learns what not to show.
The model itself does not “understand” content the way a person does.
It converts articles into vectors, compares them with user patterns, and scores likely matches with ranking features like recency, relevance, and predicted engagement.
A simple version looks like this:
- Candidate generation: The system pulls a larger pool of possible articles.
- Feature scoring: It measures signals such as similarity, freshness, and prior behavior.
- Ranking: It sorts results by predicted usefulness, not just topic match.
That process has limits.
Sparse data makes new users hard to read, while thin content gives the model too little to work with.
It also misses nuance sometimes.
A reader might want a beginner guide after reading advanced material, and the model can miss that shift unless the signals are broad enough.
The best systems treat data like clues, not commandments.
Strong AI content recommendations come from clean inputs, sensible ranking rules, and enough room for human judgment when the pattern is fuzzy.
How We Measure AI Effectiveness in Marketing
Did the AI content get more clicks but fewer leads? That mismatch happens more often than people admit, especially when AI content recommendations are tuned for engagement before they are tuned for intent.
We start with four metrics that tell the real story: click-through rate, time on page, pages per session, and conversion rate.
Return visits matter too, because strong personalized content marketing should bring people back, not just keep them hovering for one more article.
The tricky part is separating “interesting” from “effective.” A recommendation module can raise engagement by surfacing curiosity bait, while the conversion path quietly weakens.
A practical comparison table
| Metric | AI-Recommended Content | Non-Personalized Content | What It Means |
|---|---|---|---|
| Click-through rate | Usually higher when the match is relevant to the reader’s history | Usually lower because every visitor sees the same options | Better relevance gets the first click, which is the easiest win to measure |
| Time on page | Often higher when the follow-up article matches intent | Often shorter when the next click feels generic | Engagement improves when the content chain feels connected |
| Pages per session | Typically increases if recommendations create a natural reading path | Often flatter because there is less guided discovery | More page depth can signal stronger content flow, not just more browsing |
| Lead conversion rate | Can rise, stay flat, or fall depending on CTA alignment | Often steadier, but usually less personalized | This is the metric that keeps the whole system honest |
| Return visits | Often stronger when recommendations learn from prior behavior | Usually weaker unless the site already has a strong brand pull | Returning readers are a good sign that the experience feels useful |
The reader liked the topic, but not the offer, or the call to action showed up too early.
That is where a holdout group helps.
Keep one audience segment on non-personalized content, then compare CTR, conversion rate, and repeat visits over the same time window.
One useful rule: treat AI recommendations as a content system, not a vanity metric machine.
Higher clicks only matter when they support the next step.
Our own benchmarking in Scaleblogger follows the same logic: traffic quality, not traffic volume, tells you whether the model is doing real work.
When the numbers disagree, we trust conversion and return behavior before we trust raw engagement.
Where AI Content Recommendations Deliver the Most Value
Why do some recommendation blocks feel genuinely helpful, while others feel like noisy extras? The difference usually comes down to context.
AI content recommendations work best when the next piece of content already has a clear job to do.
That is why blogs, hubs, and resource libraries tend to see the strongest lift.
A reader arrives with a topic in mind, and the recommendation layer can guide them toward the next logical step instead of a random popular post.
In personalized content marketing, that little nudge often matters more than a flashy layout.
The same pattern shows up in email and landing pages.
A well-placed recommendation can match a segment’s intent, such as beginner guides for new subscribers or deeper technical pieces for people who already clicked twice.
When AI effectiveness in marketing is measured in real business terms, this is where the experience feels most natural.
- Blogs and resource libraries: These pages already attract intent-driven readers, so recommendations can surface related guides, comparisons, and next-step articles without feeling forced.
- Hubs and topic clusters: AI can connect broad pillar pages to narrower supporting content, which keeps people moving through a topic instead of bouncing after one article.
- Email campaigns: Recommendations work well when they match segment signals, like lifecycle stage, past clicks, or product interest.
- Landing pages: A single suggested article, case study, or FAQ can answer the next objection before someone leaves.
- Tech-savvy editorial planning: Teams can use recommendation patterns to decide what to write next, especially when certain topics repeatedly lead to deeper engagement.
Picture a B2B software library with beginner explainers, implementation guides, and integration docs.
A first-time visitor should probably see orientation content, while a returning reader might need a deployment checklist or a pricing breakdown.
That is a much smarter use of AI content recommendations than simply pushing the most-read article.
Tech-savvy content creators get another advantage here.
Recommendation data can expose gaps in the editorial map, like missing middle-funnel pieces or weak transitions between high-level and technical content.
That is where the value compounds.
The best systems do not just recommend content; they shape how the library grows, one useful path at a time.
What Can Make AI Recommendations Miss the Mark
Why does a model feel sharp one week and strangely off the next? Usually, it is not because the system suddenly got “worse.” It is because the signals feeding it were too thin, too narrow, or too noisy to begin with.
That shows up fast in AI content recommendations.
A new visitor with almost no history gets shoved into a tiny box.
A returning reader gets trapped in the same topic lane.
And an editorial team sees the machine picking “safe” matches that look relevant on paper but feel flat in practice.
Weak data is the first problem.
If a site only has a handful of clicks, short sessions, or shallow scroll behavior, the model learns from crumbs.
Cold-start traffic makes that worse, because the system has to guess before it has enough context to guess well.
- Thin signal, thick confidence: A model can sound certain even when it has very little to work with. That is how personalized content marketing starts looking generic.
- Narrow behavior loops: If readers only click one topic once, the system may overread that signal and keep repeating it.
- Cold-start mismatch: New users often get recommendations based on broad patterns that miss intent, timing, or urgency.
Over-personalization creates a different kind of miss.
When every block mirrors past behavior too closely, readers stop discovering anything new.
That can lead to content fatigue, especially on sites where the same theme gets recycled in slightly different packaging.
A good test is simple: if the recommendation strip feels like déjà vu, the model has probably gone too far.
- Repetition feels lazy: Showing near-identical topics again and again can make even strong content feel stale.
- Discovery gets squeezed out: Readers need some novelty, not just another version of what they already clicked.
- Engagement can flatten: The system may preserve short-term clicks while quietly reducing curiosity and breadth.
Then there is the human side.
Automation is great at pattern matching, but editorial judgment still matters when tone, timing, or brand fit are on the line.
A technically relevant recommendation can still be the wrong one if it conflicts with a campaign, a product launch, or the reading moment itself.
That tension is where AI effectiveness in marketing gets interesting.
The best teams do not let the model replace editorial sense.
They let it surface options, then keep a person in the loop when nuance matters most.
That balance is what keeps AI content recommendations useful instead of merely efficient.
How to Evaluate Tools and Platforms for Content Recommendation Workflows
Can the platform actually improve editorial decisions, or does it just create more polished noise?
That question matters because AI content recommendations only help when they sit inside a real workflow.
A smart engine that cannot talk to your CMS, your analytics, or your publishing calendar is just a demo with a nice dashboard.
The best systems support personalized content marketing without turning the team into data janitors.
They should help writers, editors, and growth leads see what deserves promotion, what should be grouped together, and where the next article should go live.
Must-have features for content teams
| Feature | Why It Matters | What Good Looks Like | Example Tools |
|---|---|---|---|
| Audience segmentation | Different readers want different paths, so generic recommendations underperform. | Segments based on behavior, topic interest, source, and engagement depth. | Dynamic Yield, Adobe Target, Bloomreach |
| Recommendation rules | Pure automation can surface odd matches that hurt trust. | Clear controls for exclusions, priorities, freshness, and content type. | Optimizely, Adobe Target, Outbrain |
| Performance reporting | Teams need to see which recommendations help reach, clicks, and downstream engagement. | Reporting tied to article views, CTR, scroll depth, and conversion events. | Google Analytics 4, Adobe Analytics, HubSpot |
| CMS integration | Manual copying wastes time and breaks consistency. | Native or API-based publishing into WordPress, Ghost, Contentful, or similar systems. | WordPress, Ghost, Contentful, Webflow |
| Content generation support | Recommendation systems work better when they connect to drafting and repurposing. | Draft assistance, headline variants, summaries, and social post generation. | Jasper, Writer, ChatGPT Enterprise |
| Experimentation tools | Teams should compare versions instead of guessing. | A/B testing, holdout groups, and clear winner logic. | Optimizely, VWO, Adobe Target |
| Governance controls | Bad approvals create brand drift fast. | Role-based access, review steps, and audit trails. | Contentful, Adobe Experience Manager, Writer |
| Taxonomy management | Weak tagging makes recommendations sloppy. | Topic clusters, tags, canonical relationships, and consistent metadata. | BrightEdge, Contentful, WordPress plugins |
It also helps teams separate shiny features from the boring stuff that actually drives results.
This is where our own workflow at Scaleblogger fits in cleanly: topic clustering, drafting, scheduling, and publishing stay connected, so recommendation logic does not drift away from production.
Questions worth asking before adopting a platform
A good sales demo can make almost anything look clever.
The real test is whether the system survives your daily mess.
- Can it explain its choices? If the platform cannot show why one article was recommended over another, trust becomes hard to maintain.
- How does it handle stale content? Freshness rules matter, especially when older pages still attract traffic but no longer deserve promotion.
- What data does it need to work well? Some tools are fine with light traffic. Others need a deeper event trail before AI content recommendations become useful.
- Can editors override it safely? Human judgment should stay in the loop when brand tone, compliance, or campaign priorities matter.
- Does it support measurement across the funnel? Strong AI effectiveness in marketing shows up beyond clicks, in assisted conversions, return visits, and time on site.
- How much setup does the team really own? If every change needs engineering help, adoption usually stalls after the pilot phase.
A platform earns its place when it makes decisions clearer, not louder.
If it fits the team’s publishing rhythm and reporting habits, the recommendation layer starts to feel useful instead of decorative.
Practical Ways to Improve Recommendation Performance
Why do some recommendation blocks quietly pull readers deeper, while others fade into the background?
Usually, the difference starts with small design choices.
A label, a card format, or a few pixels of placement can change how people read the block before they ever click it.
The smartest teams treat AI content recommendations like a living system, not a finished feature.
They test the wording, test the layout, and test where the module sits on the page.
That matters in personalized content marketing, because readers respond to cues faster than they respond to algorithms.
The safest way to improve performance is to change one thing at a time.
If you alter the label, card image, and placement all at once, you never know which change actually moved the numbers.
Test labels carefully. “Recommended for you,” “More from this topic,” and “Continue reading” can create very different expectations.
A softer label often works better near editorial content, while a more direct label can fit high-intent pages.
Vary formats with purpose. A compact text list may suit mobile readers.
Larger cards with thumbnails can work better when the page already has strong visual breathing room.
Move placement in small steps. A block above the fold gets attention fast, but it can also interrupt reading flow.
Lower placements often attract fewer impressions but better-quality clicks.
- Run one experiment per cycle. Change only the label, only the format, or only the placement.
- Keep a stable baseline. Leave one version untouched so you can compare results cleanly.
- Review results on a fixed schedule. Weekly checks are often enough for active pages, while slower pages may need longer windows.
- Feed findings back into editorial choices. If topic clusters perform well, create more of them. If certain placements underperform, move them before scaling the pattern.
That loop is where AI effectiveness in marketing starts to improve in a real way.
Analytics tells you what people are doing, and editorial judgment decides what to do next.
When those two sides work together, recommendation performance stops being guesswork.
It becomes a repeatable habit that keeps getting sharper.
Better Signals Beat Bigger Models
If a recommendation only looks smart but sends the user down the wrong path, the experience will feel random—especially for returning readers who already consumed the closest “beginner” equivalent.
So the goal isn’t to maximize prediction quality on paper. It’s to improve what happens next.
Here’s a simple way to apply everything in this article without overcomplicating it:
- Pick one downstream success event (click-to-next content, sign-up, lead conversion, or return visit) for a single content surface.
- Run a tight comparison (personalized vs non-personalized, or a controlled holdout) using the same time window.
- Add guardrails to prevent the common failure modes:
- intent mismatch (track conversion/next-step success, not just CTR)
- repetition/fatigue (monitor novelty and session depth over time)
- cold-start weakness (set safe defaults until signals mature)
- Close the loop with editorial judgment: when outcomes disagree with engagement (or when brand/compliance timing matters), override the module and update the decision rules.
When you treat recommendations as a measurable workflow—instrument, test, correct, and iterate—you stop guessing and start building a system that earns relevance over time.
Today: choose one surface, instrument the downstream event, and adjust the rules based on what improved the next step, not what merely increased attention.
