You publish detailed, well-optimized posts and still lose visibility to answer boxes and chat responses.
Search visitors arrive with questions, but the page that used to rank for those queries no longer gets credited.
Search now leans on large language models (LLMs) like Google’s BERT and MUM, and OpenAI’s GPT-3/4.
That shift changes what ranks.
Concise, direct answers beat long-form signals alone.
Using structured data and clear FAQ sections helps search systems map answers back to your pages.
Marketers are noticing the pivot: 70% say AI will play a major role in future marketing, per HubSpot.
Accenture predicts 85% of customer interactions could be handled without humans by 2025, raising the stakes for answer-first content.
If content can’t be read as an answer, it gets skipped.
Treat your pages as answer units; that changes headings, metadata, examples, and how you surface facts.
Table of Contents
Introduction: What is LLM SEO and why it matters
Search is changing faster than most content teams realize.
Large language models now sit between user queries and the content sources they see, and that changes what wins attention.
Traditional SEO tuned pages to rank in lists.
LLM SEO designs content to be selected, summarized, or quoted by conversational systems and answer surfaces instead of just ranked links.
This matters because conversational AI can either drive traffic or answer a user without a click.
HubSpot found that up to 70% of marketers expect AI to play a major role in their strategy, and Accenture projects 85% of customer interactions could be handled by AI by 2025.
Those numbers aren’t hypothetical — they signal a shift in how visibility and engagement are measured.
LLM SEO is practical and tactical.
It blends clarity, structure, and intent-focused writing so models can find and surface your content as an authoritative answer.
This FAQ focuses on those tactics and the implementation details most teams need.
The diagram illustrates the flow from a user query into an LLM-driven answer surface, then to outcomes: direct answer consumption, click-through to a site, or continued conversation.
It highlights the decision points where content either captures engagement or gets bypassed.
LLM SEO vs traditional SEO
LLM SEO reframes optimization for generative models and answer surfaces rather than only search-result rankings.
It prioritizes concise, unambiguous answers, clear context, and structured signals that models use to generate replies. LLM SEO: Content optimized to be identified, extracted, and presented as a direct answer by large language models and conversational agents.
It emphasizes answer clarity, context windows, and schema markup. Traditional SEO: Content optimized to rank in search engine result pages through keyword targeting, backlinks, and technical signals.
It often aims to win positions, featured snippets, or organic traffic.
Why search and conversational AI change content visibility
Conversational systems can consume or summarize content without sending users to the original page.
That reduces some click-based traffic but raises the value of being the authoritative source.
Google’s move toward models like BERT and MUM, and OpenAI’s influence on how text is generated, mean content must be both correct and immediately useful.
Pages that answer intent precisely are more likely to be surfaced as responses.
-
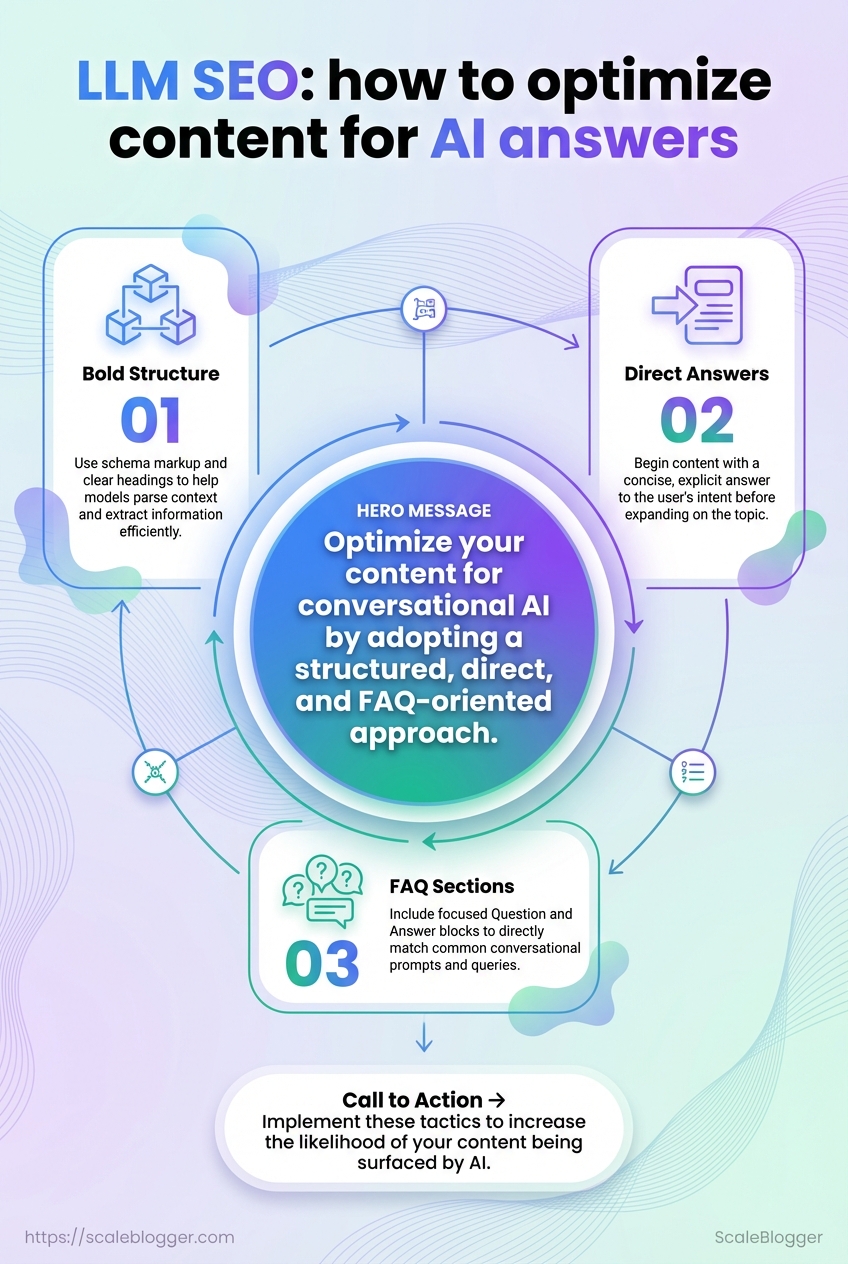
Bold structure: Use schema markup and clear headings to help models parse context.
-
Direct answers: Start with a concise, explicit answer before expanding.
-
FAQ sections: Add focused Q&A blocks to match conversational prompts.
How this FAQ is structured and who it’s for
The FAQ is built for content strategists, SEO leads, and writers who need actionable LLM-focused tactics.
Each entry explains a problem, gives concrete steps, and shows signals to monitor.
-
Tactical playbooks for content creation and structuring.
-
Implementation notes for markup, snippets, and testing.
-
Measurement guidance to track answer-surface visibility and downstream engagement.
LLM SEO doesn’t replace traditional SEO; it extends it.
Adopting LLM-aware practices preserves visibility whether users search or ask.
Why one page becomes a chat reply and another a featured snippet feels arbitrary until you look at the signals.
AI systems and answer platforms rank candidate passages not by a single metric but by a mix: relevance to the query, clarity of the wording, the content’s provenance, and the form that best fits the delivery channel.
Search engines evolved from keyword hooks to context-aware models from Google and others, while chat models from groups like OpenAI weight coherence and source blending differently.
Practical content planning treats those differences as levers you can pull: tighten phrasing for chats, add schema for snippets, and mark provenance for voice answers.
Hitting those levers consistently raises the chance an AI will surface your content instead of another source.
The rest of this section breaks down those levers, explains why each matters, and shows how to apply them.
Signals AI platforms prioritize
The short list below is what you should aim to control when creating content for snippet, chat, and voice formats.
-
Headline alignment: Use exact question phrasing in H1 and H2 to match intent quickly.
-
Concise answer presence: Lead with a 1–2 sentence direct answer early in the page.
-
Structured data: Add schema for FAQ, how-to, article, and product markup.
-
Authoritativeness: Show author byline, credentials, and outbound reputable citations.
-
Recency/freshness: Publish updates and timestamps for time-sensitive topics.
-
Citations/provenance: Link primary sources and include clear attribution lines.
-
Readability: Short sentences, active voice, and clear step sequencing.
-
Multimodal assets: Use images, transcripts, or video to support complex answers.
How clarity, authority, and structure change selection
Clear prose makes it easier for an LLM to extract an answer.
When the first paragraph answers a question directly, models prefer it because extraction is lower-cost computationally.
Authority is signaled by named sources, credentials, and citations.
Search models use those signals heavily; chat models sometimes synthesize across sources, but provenance still affects trust and ranking.
Structure—headings, lists, and schema—acts like a roadmap. It increases the chance a specific passage is selected for a snippet or read aloud by a voice assistant.
The role of freshness, citations, and provenance
Freshness: New or recently updated content ranks better for current events and evolving topics. Citations: Outbound links to recognized sources and inline attribution improve trust signals. Provenance: Explicit source notes and versioning let answer platforms prefer verifiable content.
Core Principles: How AI answers select content
Comparison of signals across platforms
Core Principles: How AI answers select content
|
Signal |
Search snippets |
Chat answers |
Voice assistants |
|---|---|---|---|
|
Headline alignment |
High — exact question-match favored for featured snippets |
Medium — model paraphrases but prefers clear question phrasing |
High — short title helps concise speech output |
|
Concise answer presence |
High — excerpted sentences gain snippets |
High — chat models prioritize short, direct answers |
Very high — brevity required for spoken replies |
|
Structured data |
Very high — schema directly feeds many snippets |
Medium — can use schema as context |
High — helps map content to voice-friendly formats |
|
Authoritativeness |
High — links and E‑A‑T style signals matter |
Medium — models synthesize but prefer reputable sources |
High — voice assistants prefer verifiable sources |
|
Recency/freshness |
High for time-sensitive queries |
Medium — recency considered for topical answers |
High — users expect up-to-date spoken info |
|
Citations/provenance |
High — explicit citations improve selection |
Medium — chats may cite but often summarize |
Very high — voice systems rely on trusted sources |
|
Readability/conciseness |
High — short, scannable text wins snippets |
Very high — chat models favor clear, coherent text |
Very high — spoken language must be simple |
|
Engagement signals (CTR, time) |
Medium — used as quality proxy |
Low — chats don’t use click data directly |
Low — voice has limited engagement telemetry |
|
Multimedia support |
Medium — images can appear in snippets |
Medium — models reference images if available |
High — audio/transcript pairs enable voice use |
|
Local relevance |
High for local queries |
Low — models may infer locale context |
Very high — voice assistants prioritize nearby results |
The table shows patterns you can exploit.
Search snippets reward structured markup and on-page signals.
Chat answers prize concise, high-quality prose that can be synthesized.
Voice assistants demand brevity, provenance, and formats that convert cleanly to speech. Imagine optimizing a page in all three directions: short lead answer for chats and voice, schema and H2 question tags for snippets, and clear source attributions for provenance.
Both marketers and writers should treat these principles as design constraints rather than optional extras.
Aligning headline language, structure, and provenance raises the chance your content becomes the answer a user actually hears.
FAQ: Practical Tactics to Optimize Content for AI Answers
When optimizing for AI outputs, focus on delivering concise and direct answers upfront, as LLMs prioritize structured content.
Ensure that your headlines and lead sentences are question-oriented and provide immediate answers.
Utilize clear headers, bulleted lists, and tables to make extraction easy for AI systems. By implementing these tactics, your content becomes more approachable for conversational AI systems, which can dramatically increase visibility in answer boxes.
Consider these guidelines as essential best practices for crafting content that aligns with AI expectations.


Automation & Workflows: Scaling LLM-aware content
Treat LLM-aware content as a production line, not a one-off writing task.
When prompts, schema, and publishing are stitched into a repeatable pipeline, output quality rises and time-to-publish falls.
Templates and a disciplined prompt library are the backbone of that pipeline; they turn tacit writer knowledge into machine-readable instructions that produce predictable, structured drafts.
This section walks through practical patterns: building prompt templates, generating structured outputs like JSON-LD and frontmatter, adding human review gates, and wiring everything into a CMS pipeline so publishes are auditable and fast. Building templates and prompt libraries
-
Base prompt: Create a single-line instruction that always runs first — e.g.,
Write an SEO article outline, H1, 150-char meta, 3 FAQs, and JSON-LD Article. -
Tone/format variants: Store short tokens for tone (
professional,casual) and format (how-to,listicle).Use them to parameterize the base prompt.
-
Slot definitions: Define required slots —
title,primary_keyword,audience,word_count— and enforce them at generation time.
Using automation to generate structured outputs
-
Define the output schema, then ask the model to return only that format.
Use
frontmatterkeys andJSON-LDblocks so downstream tools parse reliably. -
Auto-validate generated schema with a JSON schema validator before staging the draft.
-
Produce companion assets: suggested
slug, social captions, and image prompts for downstream creative automation.
Quality control: human review and validation checkpoints Editorial checkpoint: A human signs off on narrative accuracy and voice before SEO changes. SEO/schema checkpoint: Run automated checks for meta length, heading hierarchy, and Article JSON-LD completeness; flag failures. Sampling review: For high-volume pipelines, review 10% of published pieces weekly and record error categories to refine prompts. Integrating content ops with publishing pipelines
-
Staging-first flow: Push drafts to a staging site via API; require human approval before promoting to production.
-
Event-driven pushes: Use webhooks to trigger validators, image generation, and sitemap updates after approval.
-
Audit trail: Log prompt version, model used, and reviewer sign-off in content metadata for compliance.
The video shows a live run of a prompt → draft → schema markup → publish workflow and highlights the validation steps to block bad outputs.
Watch it to see how prompts map to JSON-LD and production-ready HTML.
Automation accelerates scale but only when paired with clear templates and human checkpoints.
Treat prompts and schema as versioned assets and the pipeline becomes the team’s single source of truth. Scaleblogger is an example of a platform that ties template-driven drafting to automated publishing, useful when exploring pipeline options.
Search models read pages like a structured data buffet: the cleaner the plate, the easier it is to serve an answer.
Implementing precise schema, tidy HTML, and clear API endpoints gives large language models the context they need to state facts, cite sources, and choose what to surface as an answer.
Practical wins come from small, repeatable patterns.
Add the right JSON-LD blocks, keep headings semantic, publish machine-friendly summaries, and expose provenance via APIs or accessible data endpoints.
These are not cosmetic changes — they change how models interpret relevance and trust.
Which schema types matter most for AI answers
Structured data that ties content to a specific intent or fact bundle gets prioritized by answer systems. Use schemas that encapsulate Q&A formats, procedures, and factual entities so models can extract discrete pieces of truth.
-
FAQPage: Marks question–answer pairs for direct extraction into answers or snippets.
-
HowTo: Encodes steps and tools so procedural content can be converted into step lists in replies.
-
Article / NewsArticle: Flags publishing metadata, author, date, and headline for provenance and recency signals.
-
Product: Supplies specs, prices, and availability for commerce queries.
-
Recipe / VideoObject: Surfaces structured steps, timings, and media captions for multimodal answers.
-
Dataset / DataCatalog: Signals machine-readable datasets and links back to primary sources when models need provenance.
HTML best practices: headings, summaries, metadata
HTML matters because models still read semantics from markup. Use h1–h3 to map questions and sub-answers; avoid styling headings as divs or spans.
-
Clear headings: Put the page’s primary question in
h1and supporting sub-questions inh2/h3. -
Machine summaries: Add a concise and a visible summary paragraph near the top for quick extraction.
-
Canonical + hreflang: Signal the preferred source and language to prevent duplicate-answer confusion.
-
Open Graph / Twitter Card: Provide consistent titles and images so third-party systems and LLMs see matching metadata.
API and data access considerations for provenance
When answers need to cite or verify facts, accessible APIs beat buried PDFs every time.
Expose minimal, authenticated endpoints that return JSON with timestamps and source IDs.
-
Provenance endpoints: Offer
/api/source/{id}returningauthor,published, andlicensefields. -
Versioned data: Use date-stamped endpoints or
ETagheaders so models can prefer fresher records. -
Rate-limited open access: Provide public read endpoints for basic data and authenticated tiers for heavy use.
-
Machine-readable licensing: Include
licensefields and linked machine-readable license docs to reduce citation friction.
Technical Signals: Schema, HTML and APIs
|
Signal |
Implementation |
Why AI cares |
|---|---|---|
|
JSON-LD |
Add structured Q/A pairs for each on-page question |
Enables direct extraction of answers |
|
|
Mark ordered steps and tools with |
Converts content into step-by-step replies |
|
|
Include |
Supplies provenance and recency signals |
|
|
Include |
Allows factual answers about specs and availability |
|
|
Add |
Helps multimodal systems pull accurate media text |
|
|
Publish dataset metadata and |
Lets models point to raw data for verification |
|
Canonical & hreflang |
Add |
Prevents duplicate answers and language mismatches |
|
API provenance endpoint |
|
Provides machine-verifiable source details |
|
ETag / Last-Modified headers |
Implement on content and API responses |
Signals freshness to model pipelines |
|
License metadata |
Add machine-readable |
Clarifies reuse rights for quoted material |
The checklist above is ready to paste into a deployment plan or hand off to devs as-is.
Implementing these signals is low-friction and yields disproportionate gains in how reliably models surface and cite your content.
Start with schema for your top 20 pages, tidy the HTML on those pages, and add a minimal provenance API for any data-driven article.
The clearer your signals, the more confidently models will present your content.
Measurement: How to track LLM-driven discoverability and ROI
Measuring whether LLMs are surfacing your content feels different from classic SEO.
Instead of just rank positions, you need to watch signals that show content being selected as an answer or distilled into assistant responses.
That means combining traditional metrics with new proxies that indicate AI visibility.
The goal: detect when an LLM is exposing your content and then connect that exposure to real outcomes like leads, signups, or revenue.
You need a repeatable measurement plan that treats AI impressions as a distinct channel and stitches them into existing attribution models.
Which metrics indicate AI answer visibility
Start with the usual search telemetry, but read it through an LLM lens.
These metrics act as early-warning signs that an answer model is using your content.
-
Impressions in answer features: Track
impressionson pages that target questions; spikes often mean snippet or answer exposure. -
Answer clicks / click-through rate: Monitor clicks from pages with Q&A structure; falling CTR with rising impressions suggests the content is shown as a summary.
-
Visibility in zero-click queries: Measure landing pages with low downstream navigation; higher bounce with engagement signals can still mean successful answer placement.
-
Voice and assistant triggers: Track traffic labeled for voice or assistant sources where available in analytics.
-
Engagement with structured snippets: Record interactions on FAQ blocks or rich results — they correlate with LLM extraction.
-
Conversion micro-events: Instrument micro-conversions (time on answer, read-through, CTA hover) to detect intent even when main conversion is delayed.
Attribution challenges and practical fixes
Attribution breaks down when an LLM surfaces a passage but the user never clicks through.
That disconnect needs layered solutions.
-
Use deterministic events: log micro-interactions on-page and server-side to capture late conversions tied to an initial answer exposure.
-
Build a persistent identifier: append session tokens to answer-targeting URLs so downstream visits can be linked back to the original exposure.
-
Combine models: use a last non-direct credit with weights for answer impressions plus click events to estimate influence.
-
Bring offline conversions in: stitch CRM outcomes back to answer impressions using hashed user IDs where privacy rules allow.
-
Run time-window attribution: assign fractional credit to answer exposures within a 7–30 day lookback window.
A/B testing content for answer performance
Treat answer-targeted copy as a variant you can test like any UX element.
Small changes in phrasing or structure can flip whether an LLM extracts your content.
-
Create two variants: one with concise Q/A lead-ins, the other with narrative context.
-
Randomize traffic at page-template level to isolate extraction effects.
-
Measure differential lift on
answer impressions,answer clicks, and downstream conversions. -
Iterate on schema and lead paragraphs, since those are what models preferentially consume.
The dashboard mockup shows a compact view: answer impressions and clicks over time, conversion micro-events, and a channel-attribution heatmap. Use it to prioritize pages that move both visibility and revenue.
Measuring LLM-driven discoverability blends signal engineering with classic analytics.
Track answer-native metrics, fix attribution gaps, and test variants until the data points consistently map to business outcomes.
📥 Download: Download Template (PDF)
Risks, Compliance & Brand Safety
Models that sound confident can still be wrong.
Hallucinations and subtly false claims are the single biggest operational risk when LLMs answer on behalf of a brand.
Left unchecked, those errors damage trust, invite legal exposure, and amplify reputational harm faster than any human error ever could.
Treating automation like a publication workflow fixes many problems. Build a verification layer that pairs model output with source links, human sign-off rules, and immutable logging.
Expect this to be a cross-functional program: product, legal, editorial, and security must share ownership to keep answers safe and defensible.
Managing hallucinations and misinformation
Stop guessing after generation.
Use a short, enforceable checklist that every automated reply must pass before publishing.
-
Query-level verification: require the model to return cited sources for every factual claim and an explicit confidence flag.
-
Automated cross-checking: run claims through a secondary fact-checker or retrieval system that verifies quoted passages against trusted corpora.
-
Human review gates: route anything above a defined risk threshold to an editor or subject-matter expert before publishing.
-
Post-publication monitoring: continuously scan live outputs for user flags, correction requests, and anomaly signals.
-
Automated provenance: always attach source metadata when the model asserts facts.
-
Confidence thresholds: block or flag answers below a set confidence score.
-
Escalation rules: define who approves high-risk topics like medical, legal, or financial content.
Legal and copyright considerations for LLM outputs
Copyright and attribution are trickier when outputs mix learned patterns with verbatim excerpts.
Contracts and content policies must make training data and reuse rights explicit.
That includes vendor clauses about dataset provenance and a requirement to surface sources for quoted material.
If an automated answer reproduces a copyrighted passage, treat it like any republished content: seek license, trim to fair-use-safe excerpts, or paraphrase with attribution.
Keep an auditable trail: time-stamped logs, model version IDs, and the retrieval snapshot used to generate the answer.
OpenAI’s research on model behavior and Google’s work on integrating LLMs into search are useful technical references for how models form outputs and why provenance matters (see https://openai.com/research/ and https://ai.googleblog.com/).
HubSpot and Accenture market data also underline why firms are accelerating AI adoption while wrestling with these exact risks.
Brand tone and safety in automated answers
Voice is safety.
Define a short, machine-readable brand style guide that includes prohibited phrases, safety gates, and fallback wording for unknowns.
-
Tone rule: keep answers concise, neutral, and source-linked when making claims.
-
Deflection pattern: if a query exceeds the brand’s verified scope, respond with a safe deferral template and offer a human follow-up.
-
Safety filters: block or sanitize outputs containing hate, self-harm, or privacy-invading content.
Hallucination: A confident-sounding falsehood produced by a model. Provenance: The chain of sources and model metadata that justify a specific answer. Escalation threshold: A predefined risk level that requires human approval before response publication.
Operationalize these controls, measure false-positive and false-negative rates, and iterate the policy quarterly.
Do this and automated answers will protect the brand instead of exposing it.
Every content team needs a compact, action-first checklist they can run before publishing.
This section gives two focused checklists — one for creators and one for engineers/publishers — plus a compact table you can print or export.
The goal: make LLM-friendly signals obvious and repeatable.
LLMs favor clear answers, trustworthy context, and reliable technical signals.
Remember the industry backdrop: many marketers already expect AI to shape strategy (roughly 70% by some reports), and automation will handle a growing share of interactions in the near term.
Keep those trends in mind when prioritizing changes. LLM-aware copy: Use concise answer-first headings and a visible short answer near the top of the page. Structured snippet: Place a 1–2 sentence summary in a dedicated HTML element (e.g., a div with a clear heading) so models can extract it easily.
Short checklist for content creators Start with crisp, scannable answers that LLMs can copy into replies.
Use these editing checks before you hit publish.
-
Answer-first heading: Put the one-line answer in the H1/H2 within the first 50–100 words.
-
Support with sources: Add inline citations or links for any factual claims, especially numbers.
-
Micro-FAQ: Include 3–6 FAQs that restate user intents in natural language.
-
Plain-language snippets: Add 1–3 short summary sentences that can serve as direct answers.
-
Semantic variations: Add 2–4 alternate phrasings of the main query within the body.
-
Intent alignment: Map each section to a clear user intent (inform, compare, act) and label it in the editor.
Checklist for engineers and publishers Technical signals move content from page to answer.
These checks reduce friction for crawlers and LLM-readers.
-
Schema markup: Implement
Article,FAQPage, andHowTowhere applicable. -
Clean HTML: Ensure critical text is not inside heavy scripts or lazy-load blocks.
-
Fast, consistent metadata: Serve canonical tags, Open Graph, and consistent titles server-side.
-
Stable URLs & redirects: Avoid frequent URL changes; preserve old slugs with 301s.
-
API access: Provide an endpoint or sitemap exposing recent content and score metadata.
-
Monitoring hooks: Emit signals to analytics when an FAQ or summary is updated.
Quick Reference: LLM SEO Checklist
|
Action group |
Practical checks |
Quick implementation tips |
|---|---|---|
|
Creator-focused checks |
Answer-first heading; short summary sentence; 3–6 FAQs; semantic variations; inline citations; intent labels |
Use CMS templates with summary fields; add an FAQ block; require source links in editor |
|
Engineering & publishing |
Schema ( |
Automate schema generation; run accessibility/HTML-text audits; expose content API for analytics |
|
Measurement & maintenance |
Track answer-impressions; CTR from snippets; freshness flagging; automated content rescoring; rollback plan |
Add custom events for summary clicks; schedule monthly rescans for high-value pages |
The table groups practical actions with quick tips so engineering and editorial tasks can be assigned at a glance.
The infographic summarizes the top 10 LLM SEO actions for quick sharing with teams. It highlights who owns each task and where to add the change in a typical content pipeline.
Use these checks as a pre-publish gate.
Repeat them monthly for high-value pages so answers remain accurate and discoverable.
Further reading and resources
If you want to move from theory to repeatable experiments, this is the shelf you’ll return to most often.
Pick a paper to test, a small toolchain to deploy, and a handful of prompts and schema snippets you can paste into a CMS template.
The items below are chosen for fast lift: they let a content team run controlled tests, instrument delivery, and iterate based on measurable signals rather than guesses.
Keep a lab document that records prompts, model versions, and outcome metrics for every run.
Treat this list as living.
New papers and libs arrive quickly from OpenAI and Google, and industry adoption stats (for example, HubSpot and Accenture reporting high expectations for AI in marketing and customer interactions) mean experimentation now pays off later.
Recommended experiments and whitepapers
Run experiments that isolate one variable at a time: prompt phrasing, schema presence, answer length, or snippet-focused metadata.
-
OpenAI model behavior: compare responses from
gpt-3.5vsgpt-4on the same prompt to see answer brevity and factuality differences. -
Search LLM ranking signals: test pages with and without
FAQschema to measure whether answer surfaces change in query logs. -
Answer format A/B test: publish two versions—concise bullet answer vs long-form narrative—and track CTR and session depth.
-
Whitepaper deep reads: prioritize foundational papers from OpenAI and Google to understand model capabilities and limitations.
-
Organizational benchmarks: use HubSpot/Accenture trends to shape experiment scope and stakeholder expectations.
Tools and libraries for LLM-aware publishing
Pick tooling that fits your stack: lightweight SDKs for API calls, orchestration layers for content pipelines, and CMS connectors for fast publishing.
-
OpenAI API: core for querying models and testing prompt variants.
-
Hugging Face Transformers: local model experimentation and fine-tuning.
-
LangChain (orchestration): chaining prompts, retrieval, and caching for reproducible pipelines.
-
Platform connectors: platforms like https://scaleblogger.com help automate drafting, scheduling, and republishing across channels.
-
Monitoring stacks: add logging and metrics to capture model version, prompt text, and downstream click/engagement signals.
Templates, prompts and schema snippets to copy
Keep a short library of proven prompts and schema fragments you can drop into drafts or CMS templates.
-
Prompt — concise answer:
Answer the query in two short paragraphs and provide one bullet list of actionable steps. -
Prompt — fact-checking pass:
List any claims that need citations and return a confidence score (0–1) for each claim. -
FAQ schema snippet:
json
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Question text here",
"acceptedAnswer": {
"@type": "Answer",
"text": "Concise answer text here."
}
}
]
}-
Metadata template: include a short
og:descriptionmirror of the top answer (60–90 characters) and adata-model-versionmeta tag for observability.
Bookmark the papers, keep a reproducible prompt log, and instrument everything you publish.
Small, measurable experiments compound into reliable strategies.
Conclusion
From pages to answers: your first moves
Prioritizing which pages to reshape for AI answers is the single action that most reliably increases discoverability and engagement.
Converting a top-performing blog post into short Q&A snippets, adding FAQ schema and clear HTML anchors makes it far more likely to appear inside answer boxes.That change often produces a measurable lift in impressions and higher-quality clicks, which tracking in the Measurement section shows within weeks.Run a focused pilot: choose five pages with steady traffic and clear question intent, run 2–4 week tests, and measure impressions, click-through rate, and conversions.
Use automation where possible to repurpose answers into social posts and structured snippets, following the checklist as a guardrail so work doesn’t balloon.
If a test moves the needle, scale the pattern; if not, iterate on phrasing, schema or the answer length and run another controlled test.
Pick three pages to test today: add a question header and a 40–60 word direct answer, then mark them with FAQ schema.
Tag those URLs with UTMs and add a simple dashboard to watch answer inclusion, impressions and downstream conversions.
Tools like ScaleBlogger can automate the repetitive parts, but running one manual pilot proves the approach faster than endless planning.
