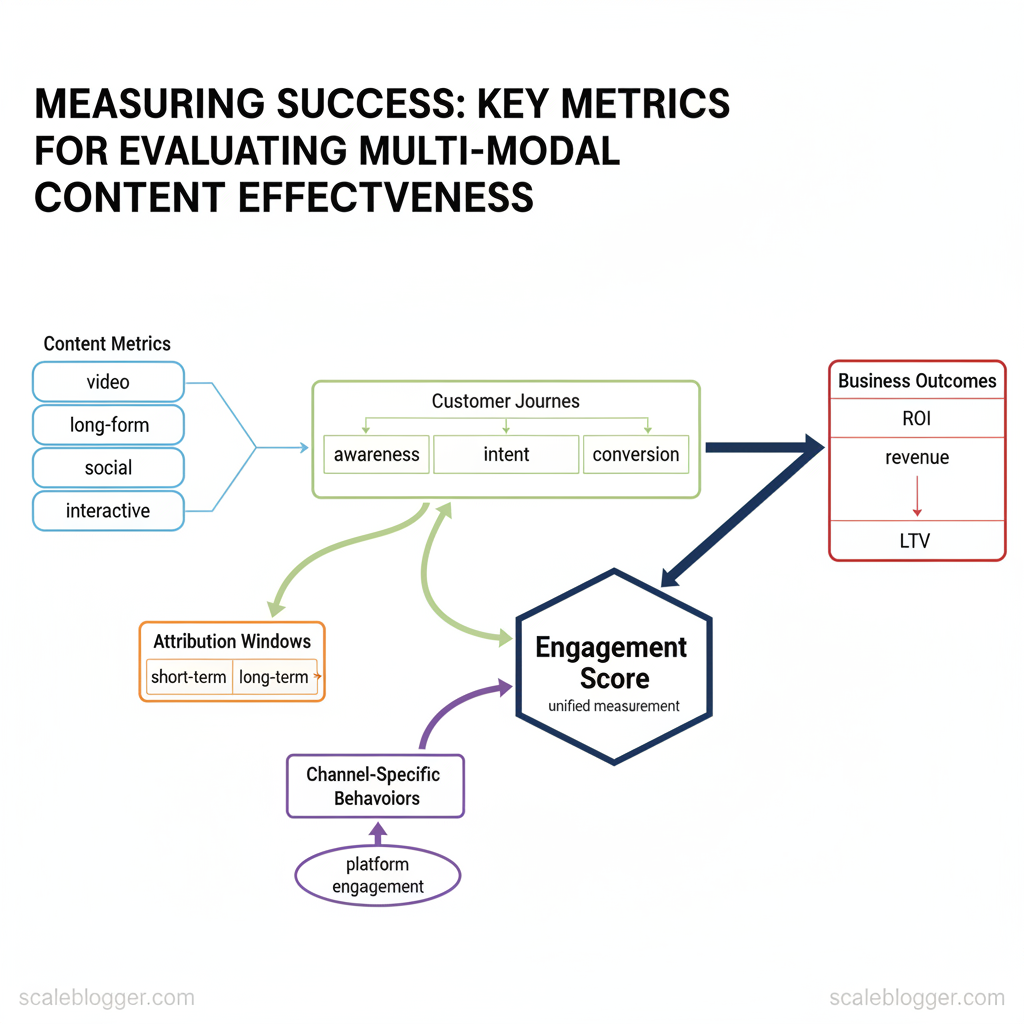
Marketing teams pour resources into multi-modal content—video, long-form, short social, interactive experiences—yet struggle to prove ROI across formats. Too often performance is judged by surface metrics rather than the interactions that drive conversions and lifetime value. Measuring success requires aligning content metrics with customer journeys, attribution windows, and channel-specific behaviors.
Industry research shows that integrated measurement reveals different truths than siloed reporting. Look beyond simple views and clicks to engagement depth, assisted conversions, and cross-channel lift. When teams adopt a consistent `engagement score` and map it to business outcomes, optimization moves from guesswork to growth.
Measurement that ties creative variations to downstream revenue converts content from cost center to predictable growth driver.
Picture a product launch where short-form ads drive awareness, long-form guides build intent, and webinars close high-value accounts. Tracking the right content performance analysis across those touchpoints surfaces which formats to scale and which to retire. This approach reduces wasted spend and sharpens creative strategy.
- How to choose measurable KPIs for each content format
- Ways to align attribution windows with buying cycles
- Methods to combine qualitative signals with quantitative metrics
- Practical steps to build a unified dashboard for cross-channel analysis
Prerequisites & What You’ll Need
Start with access and clean baseline data: without the right permissions and the last 3 months of comparable metrics, automated content workflows and performance testing will stall. Prepare tool access, basic analytics skills, and a minimal dataset so automation and editorial decisions operate on reliable inputs.
- Analytics literacy — comfort reading GA4 dashboards, behavior flows, and acquisition reports.
- UTM tagging fluency — able to craft consistent tracking strings (use a `utm_source`, `utm_medium`, `utm_campaign` pattern).
- Conversion funnel understanding — map content to funnel stage (TOFU/MOFU/BOFU) and expected KPIs.
- Basic CMS operations — publishing, editing templates, scheduling posts.
- Media platform familiarity — uploading and metadata for video/podcast hosts and social schedulers.
Industry analysis shows teams that standardize permissions and tagging reduce reporting time and attribution errors.
Practical checklist (what to gather before you start):
- Exports: last 3 months of page-level traffic, time on page, bounce/engagement rate, conversions.
- Tagging spec: a single-line UTM template like:
- Profiles: a list of account emails with required permission levels for each tool.
Step-by-Step Measurement Framework (Overview)
Begin by defining a compact, repeatable framework that maps measurement goals to execution cadence. This framework breaks the measurement program into discrete phases—discovery, instrumentation, baseline measurement, testing, scaling, and governance—so teams move from hypothesis to validated impact without losing sight of data quality. Each phase has a clear objective, an estimated timebox, and a suggested difficulty level so planners can assign resources and anticipate blockers.
Practical example: a mid-traffic blog can complete Discovery + Instrumentation in a week, collect a 3-week baseline, run a 4–6 week content experiment, then spend two weeks scaling winners — about 8–10 weeks end-to-end for a single cycle. Industry teams often parallelize phases (instrumentation while baselining smaller segments) to shorten timelines, but avoid skipping full baseline collection. Tools that automate tagging and content scoring—such as AI content automation platforms—can reduce instrumentation time and make scaling predictable. Understanding these phase-level estimates helps prioritize work and set realistic stakeholder expectations.
Step 1: Define Success — Objectives & KPIs for Each Modality
Start by naming the business outcome you need from content, then pick modality-specific goals and measurable KPIs that directly map to that outcome. This prevents vague briefs like “increase engagement” and replaces them with precise targets such as increase qualified trial signups by 20% from blog-driven traffic within 6 months. Use formulas for clarity (`conversion rate = conversions / sessions`) and set pragmatic benchmarks using historical account data or market norms when no baseline exists.
Common formulas to include in briefs
- Conversion rate = conversions / sessions
- Playthrough rate (video) = completed plays / starts
- Clickthrough rate (CTR) = clicks / impressions
- Average session duration = total time on page / sessions
| Business Objective | Content Modality | Primary KPI | Secondary KPI |
|---|---|---|---|
| Awareness | Written (SEO blog) | Organic sessions per month | Average time on page (s) |
| Awareness | Video (short-form) | Views per 30 days | Playthrough rate (%) |
| Acquisition | Landing Page / Interactive | Landing page conversion rate (%) | Cost per acquisition (CPA) |
| Engagement | Podcast / Audio | Episode downloads per month | Completion rate (%) |
| Retention | All Modalities | Returning users rate (%) | Churn reduction vs cohort (%) |
Practical tip: add one trailing KPI (e.g., assisted conversions) to capture multi-touch influence. For teams adopting automation, integrate `content scoring` from tools like Scaleblogger.com to predict performance and prioritize high-impact briefs. When targets are realistic and instrumented, teams move faster and make fewer subjective decisions.
Step 2: Instrumentation — Implement Tracking Across Modalities
Start by treating tracking as product-grade instrumentation: consistent identifiers, machine-readable events, and automated verification. Instrumentation ties distribution channels, engagement events, and backend IDs together so analytics teams and content owners can trust the numbers and act quickly.
- Taxonomy root: Start with verbs: `viewed_article`, `cta_clicked`, `form_submitted`, `video_started`.
- Parameter set: For each event include `content_id`, `content_type`, `author_id`, `campaign`, and `engagement_value`.
- Version events: Add a `schema_version` parameter so downstream ETL knows how to parse older events.
- Persist a `content_id` across CMS, analytics, and CRM.
- Map user identifiers: Use `cross_platform_user_id` to join anonymous sessions to logged-in profiles where privacy allows.
- Store mappings in a lightweight lookup service or within the content platform.
Practical tip: integrate this instrumentation with content workflows—embed UTM templates in editorial briefs and enforce event hooks in publishing pipelines. For teams scaling content operations, consider platforms that automate tagging and audits; tools like Scaleblogger.com can help automate pipeline steps and enforce taxonomy consistently. Understanding these practices lets teams move faster without sacrificing data quality.

Step 3: Data Collection & Centralization
Collect and normalize every content, traffic, and engagement signal from each platform into a single canonical store so analysis and automation operate from the same truth. Start by cataloging data sources, choose pull methods that match access patterns, and apply consistent normalization rules (timezones, user IDs, content IDs) before ingesting. This reduces duplicate work, prevents attribution errors, and enables automated workflows to act on standardized records.
Prerequisites
- Access credentials: API keys, CSV exports, SFTP credentials for each source.
- Data schema: agreed field list (e.g., `content_id`, `published_at`, `author_id`, `page_views`, `search_queries`).
- Storage choice: cloud data warehouse, data lake, or a managed analytics DB.
- Extraction tools: `curl`, Postman, or an ETL tool (e.g., Airbyte, Fivetran).
- Storage: BigQuery/Redshift/Snowflake, or a centralized PostgreSQL.
- Orchestration: cron, Airflow, or an automation layer such as the automation features in Scaleblogger.com for content pipelines.
- Validation utilities: scripts in Python/SQL and simple dashboards for reconciliation.
Example API pull (Python) “`python import requests, json res = requests.get(“https://api.example.com/posts” headers={“Authorization”:”Bearer TOKEN”}) posts = res.json()
Map fields
normalized = [{“content_id”: p[“id”], “published_at”: p[“date”], “title”: p[“title”]} for p in posts]Bulk insert/upsert into DB
“`Normalization rules (common) Timezone standardization: Store everything in `UTC` and render in local time only at presentation layer.* Identifier mapping: Create a single `author_id` namespace to join analytics and CMS records.* Canonical content ID: Generate a stable `content_id` using CMS ID + source slug.*
Validation steps and sanity checks
- Row counts: verify expected rows per source vs. previous run.
- Checksum or hash: detect silent changes to content bodies.
- Dashboard reconciliation: compare aggregated metrics against platform dashboards within a 5% variance tolerance.
- If API rate limits block extraction, implement incremental syncs using `modified_after` cursors.
- If duplicates appear, inspect `upsert` keys and ensure idempotent loads.
- If timezones mismatch, backfill corrected `UTC` values and mark affected records with a `corrected` flag.
- Centralized, normalized dataset enabling automated content scoring, reliable attribution, and consistent feeds into publishing and reporting systems. When implemented well, teams spend less time fixing data and more time optimizing content.
Step 4: Analysis — Interpreting Metrics and Attribution
Begin by converting disparate metrics into a single, comparable view so decisions are based on signal, not noise. Normalization and a defensible attribution choice let teams prioritize content investments and optimize channels that truly move conversions.
Prerequisites
- Data access: GA4, CRM conversion logs, ad-platform reports
- Identifiers: UTM taxonomy, campaign IDs, content IDs
- Baseline KPIs: target CPA, LTV, engagement thresholds
- Analytics platform: GA4, Adobe, or a BI tool
- Attribution engine: native analytics models or `data-driven` solutions
- Spreadsheet/SQL: for normalization and score calculations
- Why normalize: different scales (time on page vs. revenue) distort comparisons.
- What success looks like: top 10% of content by composite score consistently outperforming baseline CPA.
- Performance marketing goal: favor `last-touch` for short-funnel buys.
- Brand or discovery goal: favor `first-touch` or `time-decay` to credit early awareness.
- Complex, multi-step journeys: adopt `linear multi-touch` or `data-driven`.
- Funnel visualization: conversion rates at each stage, segmented by channel.
- Cohort retention charts: returns and LTV by acquisition month.
- Time-to-convert histogram: identifies long-tail paths requiring nurture.
Practical example
| Attribution Model | Best Use Case | Pros | Cons |
|---|---|---|---|
| Last-touch | Short-funnel conversions | Simple, quick insights | Over-credits final touch |
| First-touch | Awareness/brand lift | Highlights discovery channels | Ignores later conversion drivers |
| Linear multi-touch | Balanced credit across journey | Fair distribution across touchpoints | Can dilute impact signals |
| Time-decay | Long sales cycles with nurture | Credits recent influences more | Requires time-window tuning |
| Data-driven | Complex journeys with ample data | Most accurate when trained |
Key insight: choose the model that maps to your objective—awareness, consideration, or conversion—and validate by testing shifts in composite scores and business metrics after reassigning credit.
When analysis and attribution are coherent, teams make faster, more confident tradeoffs between content creation, paid amplification, and nurturing. Understanding these mechanics reduces guesswork and lets creators focus on high-impact work.
Step 5: Reporting & Dashboards — Communicate Insights
Begin by treating reporting as a delivery mechanism for decisions: dashboards should reduce ambiguity and point teams to the next action. Design two complementary views — an Executive dashboard for direction-setting and a Tactical dashboard for execution — then standardize templates and alert thresholds so every stakeholder knows what to do when a metric moves.
Executive vs Tactical components
- Executive — high level: traffic trend, conversions, topical cluster performance, ROI by channel, and a 90-day forecast.
- Tactical — operational: page-level clicks, impressions, publish cadence, keyword ranks, content scoring, and backlog velocity.
- Common crosswalks: link metrics to business outcomes (e.g., leads per topic cluster) so both views speak the same language.
Dashboard specs — fields to include
- Title: clear and time-bound.
- Owner: responsible person.
- Update cadence: `daily/weekly/monthly`.
- Primary metric: the one metric that changes decisions.
- Secondary metrics: 3–5 contextual metrics.
- Data sources: GA4, Search Console, CMS, CRM.
- Action links: direct links to content, task in project tool, and source queries.
Alerting thresholds and example action items
- Alert: CTR < 1% for prioritized pages → Action: run headline A/B within 48 hours.
- Alert: Sessions down 20% week-over-week on a core cluster → Action: audit backlinks and check indexing within 24 hours.
- Alert: Publish failure → Action: rollback draft and notify editor immediately.
Step 6: Iteration — Testing, Learning, and Optimization
Prerequisites: a baseline KPI set (traffic, CTR, conversion), tracking in place (GA4, server logs, or analytics API), and a content backlog ready for experiments. Tools/materials needed: access to publishing CMS, A/B testing framework or simple experiment tracker, a sample-size calculator (or `statsmodels`/`G*Power`), and a shared results spreadsheet or dashboard. Time estimate: plan biweekly sprints for rapid tests, monthly reviews for statistical significance, quarterly strategy adjustments.
Start by prioritizing experiments using a simple scoring model so teams run the highest-impact tests first. Use either `ICE` (Impact, Confidence, Ease) or `PIE` (Potential, Importance, Ease) to rank ideas quickly. Score each idea 1–10 and sort; this prevents chasing low-value optimization.
Practical examples
- Content headline test: headline A vs B → 12% CTR lift on long-form; replicated across 8 pages → rolled into headline templates.
- Structured data: adding FAQ schema → improved rich result impressions; implemented as a sitewide pattern for category pages.
Understanding and operationalizing this iterative cycle lets teams convert experiments into repeatable improvements while keeping velocity and quality aligned. When tests are run thoughtfully, learning compounds into measurable growth.

Troubleshooting Common Issues
Missing or inconsistent metrics are usually a pipeline or identity problem rather than an algorithmic mystery. Start by isolating where the gap appears — at collection, ingestion, or reporting — then apply targeted fixes that restore confidence in the numbers. Below are practical diagnostics, fixes, and checks that resolve the five most frequent measurement headaches.
Common diagnostics and quick tactics
- Check quotas and schedules first: Missing or delayed data often comes from exhausted API quotas or failed export jobs.
- Validate identity stitching: Attribution mismatches frequently trace to cookie expiration, inconsistent `user_id`, or multiple identity providers.
- Dedupe at ingestion: Duplicate events are best handled by event-level keys (`event_id`) and idempotent inserts.
- Reconcile raw logs: When platform and warehouse numbers diverge, compare raw delivery logs and export manifests before adjusting business metrics.
- Preserve UTMs: Social platforms or link shorteners commonly strip UTMs; enforce `utm` preservation on redirect services.
Code example — dedupe by event_id (Postgres) “`sql CREATE TABLE events_dedup AS SELECT DISTINCT ON (event_id) * FROM events_raw ORDER BY event_id, received_at DESC; “`
| Symptom | Likely Cause | Immediate Fix | Verification Step |
|---|---|---|---|
| No video views in dashboard | Tracking pixel blocked / SDK disabled | Re-deploy pixel and confirm SDK initialisation | Check network logs for 200 on pixel and `video_play` events |
| Duplicate conversions | Retries without idempotency / multiple SDK fires | Dedupe on `event_id` or composite key | Run distinct count by `event_id` and compare totals |
| Mismatch between platform and warehouse numbers | Export failures / partial uploads / time zone shifts | Re-run exports; align ETL timezone handling | Compare raw export row counts and MD5 checksums |
| Low sample size for experiment | Short test duration / heavy segmentation | Increase traffic or broaden cohorts | Monitor statistical power and daily sample counts |
| UTMs stripped from social links | Redirects or shorteners drop query params | Preserve or append UTMs server-side | Click test links and inspect landing page URL parameters |
When event-level troubleshooting grows complex, automating checks and alerts reduces firefighting. Consider integrating monitoring into the CI/CD pipeline or using an automated content pipeline like `AI-powered content automation` to keep measurement feeds healthy. Understanding these principles helps teams move faster without sacrificing data quality.
📥 Download: Content Measurement Checklist (PDF)
Tips for Success & Pro Tips
Start by treating measurement as an operational system, not an afterthought. Establishing strong governance, automating data flows, and building a measurement culture prevents noisy dashboards and ensures decisions rest on reliable signals.
Practical example: “`sql CREATE VIEW canonical_page_metrics AS SELECT page_id, date, sessions, conversions FROM raw_analytics WHERE is_valid = TRUE; “`
- Scheduled pulls: Set ETL runs at predictable intervals (hourly for real-time signals, nightly for heavier aggregations).
- Automated validation: Run checksum or row-count checks after each load and flag mismatches.
- Anomaly alerts: Configure alerts for metric drift (e.g., >20% change week-over-week) and route them to a dedicated Slack channel.
- Monthly insight memos: Produce a one-page memo with 3 wins, 2 problems, and 1 experiment idea. Distribute to stakeholders and archive in the knowledge base.
- Quick wins log: Capture fast, testable actions that came from data—this builds trust and shows immediate ROI.
- Review cadences: Hold a 30-minute monthly review with product, content, and growth to align on actions.
- If metrics disagree across tools, trace back to the ingestion timestamp and filters; mismatches are usually schema or time-zone related.
- If alerts fire too often, widen thresholds and implement a suppression window to avoid alert fatigue.
- Content scoring framework spreadsheet: map content → intent → KPI → benchmark.
- Automated report template with parameterized date ranges to reuse across teams. Consider integrating with AI content automation like `Learn how to automate your blog` at Scaleblogger.com for pipeline orchestration.
Appendices: Templates, Queries, and Resources
This appendix contains practical, ready-to-drop-in assets for measurement, experimentation, and executive reporting. Use the CSV and SQL examples to standardize event collection, drop the executive summary and experiment plan into stakeholder decks, and apply the UTM sheet to keep acquisition reporting accurate. These assets reduce ambiguity between engineering, analytics, and content teams so decisions happen faster.
Prerequisites
Tools / materials needed
- Spreadsheet (Google Sheets or Excel) for taxonomy and UTM sheet.
- SQL client (BigQuery, Snowflake) for queries.
- Slide deck template for executive summaries and experiment briefs.
Code and templates
Event taxonomy CSV example (first rows) “`csv event_name,category,action,label,value,required,notes page_view,engagement,view,page_path,,yes,auto-collected cta_click,conversion,click,button_id,,yes,track all CTAs newsletter_signup,conversion,submit,form_id,,no,include user_id if available “`
Cross-modality aggregation SQL (BigQuery example) “`sql SELECT user_id, MIN(event_timestamp) AS first_touch, COUNTIF(event_name=’page_view’) AS page_views, COUNTIF(event_name=’cta_click’) AS cta_clicks FROM `project.dataset.events_*` WHERE event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE() GROUP BY user_id; “`
Executive summary template (slide-ready)
- Objective: one sentence goal.
- Metric focus: primary KPI + baseline.
- Key findings: 3 bullets.
- Recommendation: 1 action with confidence level.
- Next steps & owners: list with due dates.
| Template | Purpose | Format | How to Use |
|---|---|---|---|
| Event taxonomy CSV | Standardize events | CSV | Import to GTM or share with devs |
| Cross-modality aggregation SQL | Aggregate events by user | SQL (BigQuery) | Run as daily job in scheduler |
| Executive summary template | Stakeholder-ready report | PPT / Google Slides | Copy into weekly reporting deck |
| Experiment plan template | Structured A/B testing | Doc / Google Doc | Use for pre-launch review & approvals |
| UTM naming convention sheet | Consistent campaign tracking | Spreadsheet | Reference when creating tracking links |
Understanding these resources helps teams ship experiments and reports with confidence while maintaining consistent data hygiene. When properly integrated, they convert ad-hoc measurement work into repeatable workflows that scale.
Conclusion
After investing in multi-modal content, focus shifts from volume to measurable impact: align attribution models with channel behavior, automate cross-format tagging, and normalize KPIs so short-form and long-form can be compared. Practical experiments in the field show that teams who standardized metadata and automated engagement mapping cut reporting time by weeks and uncovered underperforming formats they could optimize. Expect to establish a single source of truth, set up automated measurement pipelines, and iterate on creative based on outcome signals rather than impressions.
– Standardize tagging and metadata across formats. – Automate measurement workflows to reduce manual reporting. – Prioritize outcome metrics that map to business goals, not vanity metrics.
For teams wondering how long this takes, plan for a 4–8 week pilot to implement tagging and connect measurement; for questions about staffing, start with a small cross-functional team and scale automation; for concerns about comparability, run parallel A/B-style tests across formats. To streamline that process, platforms like Explore Scaleblogger’s AI workflows for content measurement automation can accelerate setup and surface actionable insights faster. Next step: pick one format, apply standardized tags, and automate a weekly report to see where optimization delivers the fastest ROI.
