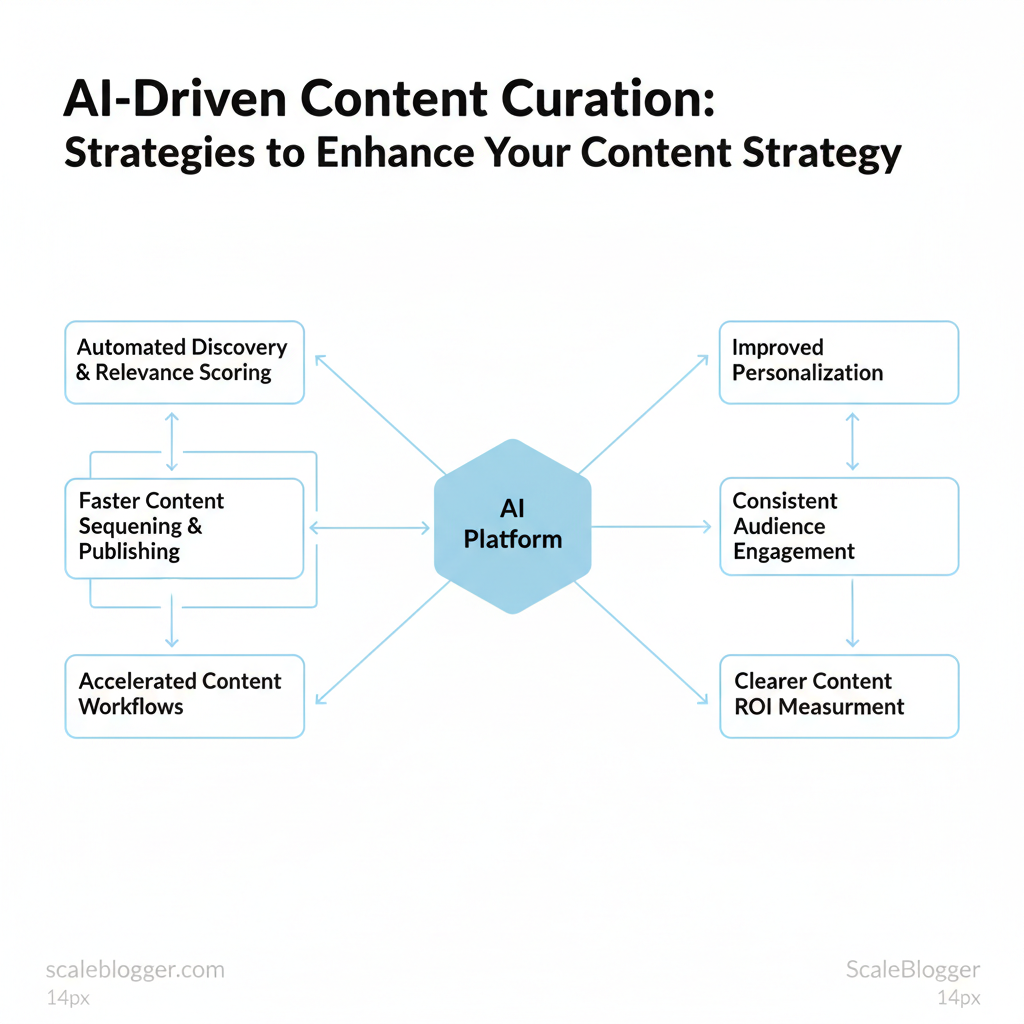
Marketing teams waste hours hunting, vetting, and sequencing content that never reaches peak impact. That friction dims audience reach and drains creative capacity across channels.
The business payoff is straightforward: more consistent audience engagement, faster iteration on topics, and clearer measurement of content ROI. The next sections unpack practical strategies for building scalable curation pipelines, selecting the right tooling, and avoiding common pitfalls.
- How to structure `content pipelines` for automated discovery and reuse
- Methods for combining human judgment with algorithmic recommendations
- Metrics to track relevance, reach, and conversion impact
- Tool selection criteria and integration patterns
- Workflow steps to move from pilot to production
Foundations of AI-Driven Content Curation
AI-driven content curation automates discovery, organization, and delivery of relevant materials so teams can scale relevance without drowning in sources. At its core it performs four repeatable tasks: discovery at scale, automatic classification, concise summarization, and audience-level personalization. These functions rely on `NLP` pipelines, semantic clustering, and behavioral signals to turn raw content streams into actionable items for editorial workflows.
When to choose AI curation versus manual curation depends on scale, cadence, and sensitivity. Industry articles on AI content strategy show that automation accelerates throughput and A/B testing of formats while assisted approaches preserve editorial voice and compliance control (see Building a Robust AI-driven Content Strategy for Enterprise). Practical implementations blend modes: automated discovery plus human validation for high-stakes outputs, or fully automated feeds for internal dashboards and alerts (see 6 AI-Driven Content Strategies + Benefits, Challenges).
| Decision Factor | Manual Curation | Assisted Curation | Automated Curation |
|---|---|---|---|
| Best use case | Editorial features, sensitive topics | Newsletters + content ops workflows | Real-time alerts, large streams |
| Speed | Hours–days | Minutes–hours | Seconds–minutes |
| Consistency | Variable (editor-dependent) | High (templates + human checks) | Very high (algorithmic rules) |
| Editorial control | Full control (tone, nuance) | Shared control (human-in-loop) | Algorithmic (policy rules) |
| Resource requirements | Senior editors, SMEs | Editors + AI tools (NLP, summarizers) | Engineering + ML ops, lower editorial headcount |
Understanding these principles helps teams move faster without sacrificing quality. When implemented correctly, this approach reduces overhead by making decisions at the team level.
Building the Data Pipeline for Curation
Prerequisites
- Access to source APIs or web crawling permissions (OAuth keys, robots.txt check) — 1–2 hours to set up.
- Storage layer (S3, GCS, or database) and a lightweight message queue (Kafka/RabbitMQ) — 2–4 hours to provision.
- Basic NLP stack (spaCy/transformers), metadata schema, and license-compliance checklist — 3–6 hours to prepare.
- API keys for major publishers and social platforms.
- ETL framework (Airflow, Prefect) or owner-built job runner.
- NLP models for topic tagging and intent scoring.
- Storage with versioning and provenance fields.
Example normalized JSON “`json { “title”:”Example”, “author”:”Jane Doe”, “publish_date”:”2025-06-01″, “canonical_url”:”https://example.com/article” “topics”:[“ai”,”content-strategy”], “intent_score”:0.87, “license_url”:”https://example.com/license” “provenance”:{“ingest_ts”:”2025-06-02T12:00Z”,”source_id”:”industry_pub_1″} } “`
Troubleshooting tips
- If topic tags drift, freeze model versions then retrain on labeled samples.
- If ingestion gaps appear, replay from crawl logs using `ingest_timestamp` markers.
| Source | Authority Score | Freshness (update freq) | Formats | License/Use Notes |
|---|---|---|---|---|
| Industry publications | High (DA 60–90) | Daily to weekly | Articles, reports, interviews | Usually copyrighted; syndication/licensing required |
| Academic papers | Very High (citation-based) | Monthly to yearly | PDFs, datasets | Often CC-BY or publisher license; check embargoes |
| Competitor blogs | Medium (DA 30–60) | Weekly to monthly | Articles, case studies | Copyrighted; use summaries and links |
| Social posts (X/LinkedIn) | Variable (low–medium) | Real-time | Short posts, threads, images | Platform TOS; store permalinks and author metadata |
| User-generated forums | Low–medium (variable) | Real-time to weekly | Threads, comments, tips | Community terms; check privacy and consent |
Understanding these principles helps teams move faster without sacrificing quality. When implemented correctly, this approach reduces overhead by making decisions at the team level.

AI Techniques and Tools for Effective Curation
Start by treating curation as an engineering problem: extract, represent, cluster, and rank. Use the right mix of NLP, embeddings, topic modeling, and ranking to turn raw signals into editorial decisions that scale.
- Automated tagging (entities, topics)
- Semantic search (embeddings index)
- Summarization (abstractive/extractive)
- Workflow integrations (CMS, analytics)
- Audit logs & data retention (compliance)
Industry analysis shows AI-driven content strategies improve throughput and personalization when engineering and editorial controls are balanced.
Practical example — embedding similarity snippet: “`python
pseudo-code: compute similarity
emb1 = model.encode(“article A”) emb2 = model.encode(“article B”) score = cosine_similarity(emb1, emb2) if score > 0.85: flag_duplicate() “`| Criteria | Small teams | Mid teams | Enterprise |
|---|---|---|---|
| Budget considerations | Low-cost options: free tiers, pay-as-you-go; Jasper starts ~$39/mo | Mid-range: $100–$1k+/mo; subscription + usage | High budget: custom contracts, volume discounts |
| Integration complexity | Low: Zapier, CMS plugins; quick setup | Medium: API integrations, SSO | High: SAML, SIEM, custom connectors |
| Customization needs | Basic: templates, prompt libraries | Advanced: fine-tuning, private models | Full: on-prem/ VPC, custom ML teams |
| Support and SLAs | Community/support docs; email | Paid support; dedicated CSM options | 24/7 SLA, enterprise success, dedicated engineers |
| Data privacy controls | Basic: anonymization options | Enhanced: configurable retention | Strict: contractual controls, data residency |
Understanding these principles helps teams move faster without sacrificing quality. When implemented correctly, this approach reduces overhead by making decisions at the team level.
Workflow Design: From Discovery to Publication
Start with discovery as the engine — identify audience signals, topic clusters, and measurable goals before producing a single draft. A disciplined workflow separates discovery, creation, review, and distribution so teams scale predictably while keeping quality high.
Templates for handoffs (example) “`markdown Brief ID: CB-2025-034 Owner: Content Lead Deadline: 2025-06-10 Target Keyword: “AI content pipeline” Primary sources: [source list] Deliverables: Long-form post, 3 social posts, meta Checks: Plagiarism ✓, Source licenses ✓, Tone match ✓ “`
Quality assurance and editorial guardrails
| QA Item | Automated Check | Human Review | Frequency |
|---|---|---|---|
| Factual accuracy | NLP fact-extractor, cross-check against cited URLs | Verify primary sources, contextual correctness | Pre-publish; spot-check weekly |
| Source licensing | Metadata scan for image/license tags, link validation | Confirm licenses, request permissions if needed | Pre-publish |
| Tone/style alignment | Style-scoring engine (brand voice model) | Editor adjusts phrasing and brand voice | Pre-publish |
| Plagiarism/duplication | Plagiarism scan (web crawl, database) | Manual similarity review and rewrite | Pre-publish |
| Sensitive content flags | Keyword/semantic sensitivity filter | Legal/DEI review; remove or reframe content | Pre-publish; incident-driven |
Understanding these principles helps teams move faster without sacrificing quality. When implemented correctly, this approach reduces overhead by making decisions at the team level.

Personalization, Distribution, and Measurement
Start by mapping audience micro-segments and delivery expectations. Personalization should begin simple — role, industry, and intent — and evolve using behavioral signals and predictive scoring to rank content relevance in real time. Implement privacy-safe personalization by minimizing PII usage, storing aggregated signals, and offering clear opt-outs.
Prerequisites
- Data access: CRM, analytics, content metadata
- Tools: recommender engine, email platform, social scheduler, dashboarding (Scaleblogger’s automated scheduling and benchmarking is a viable option)
- Governance: consent policy, retention rules
Step-by-step personalization and distribution workflow (time estimates)
Practical personalization tactics (5–8 items)
- Role-based landing: Show role-specific headlines and one targeted CTA.
- Intent triggers: Serve awareness vs. purchase content based on recent search/referrer.
- Behavioral boosting: Increase rank for content when `repeat_visit > 2`.
- Predictive ranking: Use propensity scores to prioritize high-value content.
- Privacy-first defaults: Anonymize events and keep session-only identifiers.
- Content recency decay: Reduce weight for items older than `90 days`.
- Fallback logic: Always include a high-performing generic piece when personalization confidence is low.
| Channel | Recommended Frequency | Best content format | Primary KPI |
|---|---|---|---|
| Email newsletter | Weekly or biweekly | Curated longform + links | Click-through rate (CTR) |
| Social media | 3–7x weekly (platform-dependent) | Short posts, repurposed excerpts | Engagement rate (likes/comments/shares) |
| In-app recommendations | Real-time / session-based | Short summaries, next-article prompts | CTR to content / session depth |
| Syndication partners | Monthly / per campaign | Full articles or excerpts | Referral traffic / assisted conversions |
| RSS / aggregators | Continuous (feed) | Headlines + excerpts | Feed subscribers / open rate in readers |
“AI-driven content strategies improve efficiency and predict performance” — industry analysis and practical guides outline automation and measurement approaches (Nightwatch AI-driven content strategies).
Reporting cadence and attribution
- Weekly engagement digest, monthly conversion review, quarterly cohort analysis.
- Use first-touch for discovery attribution and multi-touch / assisted conversion for nurturing insights.
- Track `time_on_content`, CTR, downstream conversion (lead, signup, revenue) as the core KPIs.
- Low CTR: refresh subject lines, test `preview_text`, re-evaluate segment relevance.
- Poor model performance: add more signals, reduce label noise, run fresh A/B tests.
- Privacy complaints: tighten retention and clarify consent flows.
📥 Download: AI-Driven Content Curation Checklist (PDF)
Scaling, Governance, and Ethical Considerations
Scaling a content curation pipeline demands deliberate structure and governance so automation increases throughput without eroding quality or trust. Start by defining who owns each stage of the pipeline, when to push work to automation versus when to hire, and how to audit for bias, provenance, and privacy as the system grows.
Prerequisites
- Clear content objectives and taxonomy
- Inventory of data sources and licenses
- Baseline KPIs and ROI targets
- Privacy impact assessment (PIA) and legal sign-off
- Content ops platform or CMS with API access (e.g., scheduler + publishing automation)
- Versioned dataset storage and provenance ledger (S3/GCS + metadata store)
- Annotation and review UI for `human-in-the-loop` checks
- Monitoring dashboard for SLAs, throughput, and bias metrics
- Audit training and source data: maintain sampled audits of training sets to detect representation gaps and under/over-representation by demographic, region, or perspective.
- Human-in-the-loop for sensitive topics: route flagged content (health, finance, legal) to a specialist reviewer before publication.
- Provenance and licensing records: store source URIs, crawl timestamps, license terms, and usage rights alongside generated content.
- Data protection and TOS compliance: implement `data minimization`, purpose-limited use of personal data, and periodic PIA reviews aligned with platform Terms of Service.
| Role | Primary responsibilities | Required skills | KPIs to measure |
|---|---|---|---|
| Content curator | Source and tag content; maintain taxonomy; initial quality filter | Research, metadata tagging, SEO basics | Assets sourced/day; accuracy of tags; ingestion SLA |
| Editor | Craft/shape content; quality and voice; final pre-publish checks | Copyediting, brand voice, fact-checking | Time-to-publish; editorial quality score; engagement rate |
| ML/data engineer | Build pipelines, model ops, feature store; monitor model drift | Python, ML pipelines, feature engineering | Pipeline uptime; model AUC/dataset drift alerts |
| Product/analytics owner | Define roadmap, prioritize features, measure impact | Analytics, A/B testing, stakeholder management | Content ROI; lift in organic traffic; experiment velocity |
| Compliance/legal | License review, privacy checks, regulatory sign-off | IP law basics, privacy regs (GDPR, CCPA) | Compliance exceptions; time-to-approval; audit findings closed |
Troubleshooting common issues
- If model drift spikes, roll back to the last validated dataset and retrain with a representative sample.
- If bias surfaces in outputs, conduct a targeted source-audit and add counter-balancing examples to training data.
- If publishing latency grows, re-evaluate manual approval SLAs and expand automation for non-sensitive checks.
After walking through audience-first templates, repeatable vetting rules, automated sequencing, and measurement loops, the path forward is clear: audit your content inventory, automate curation workflows, and measure distribution impact so effort turns into measurable reach and conversions. Teams that apply these three moves shorten planning cycles, reduce wasted creative time, and increase cross-channel engagement — a pattern corroborated by industry analysis showing meaningful efficiency gains from AI-driven strategies.
If questions remain about where to start or which workflows to automate first, begin with a small channel pilot, map inputs and outputs, and set one leading metric. For professional implementation and to accelerate setup, Explore automated content curation workflows with Scaleblogger — it’s a practical next step for turning the concepts above into repeatable systems. Research from Nightwatch also demonstrates that systematic AI-driven content approaches improve both discoverability and ROI, reinforcing that disciplined automation pays off.
