Drafts arrive faster, but the comments feel emptier: a blog calendar filled with polished posts that somehow lose the author’s voice. Content teams recognize the productivity gains of automation, yet they also notice subtle shifts in tone, nuance, and trust that cost more than time saved.
Balancing AI ethics with real human judgment isn’t a philosophical luxury anymore; it’s a daily editorial decision about what counts as honest communication. The trade-offs show up in search traffic, reader retention, and brand reputation when algorithms optimize for engagement over truthfulness. Tackling those trade-offs requires more than checklists — it demands concrete guardrails that preserve content authenticity while allowing genuinely innovative content workflows to scale.
Learn how Scaleblogger helps teams deploy AI responsibly
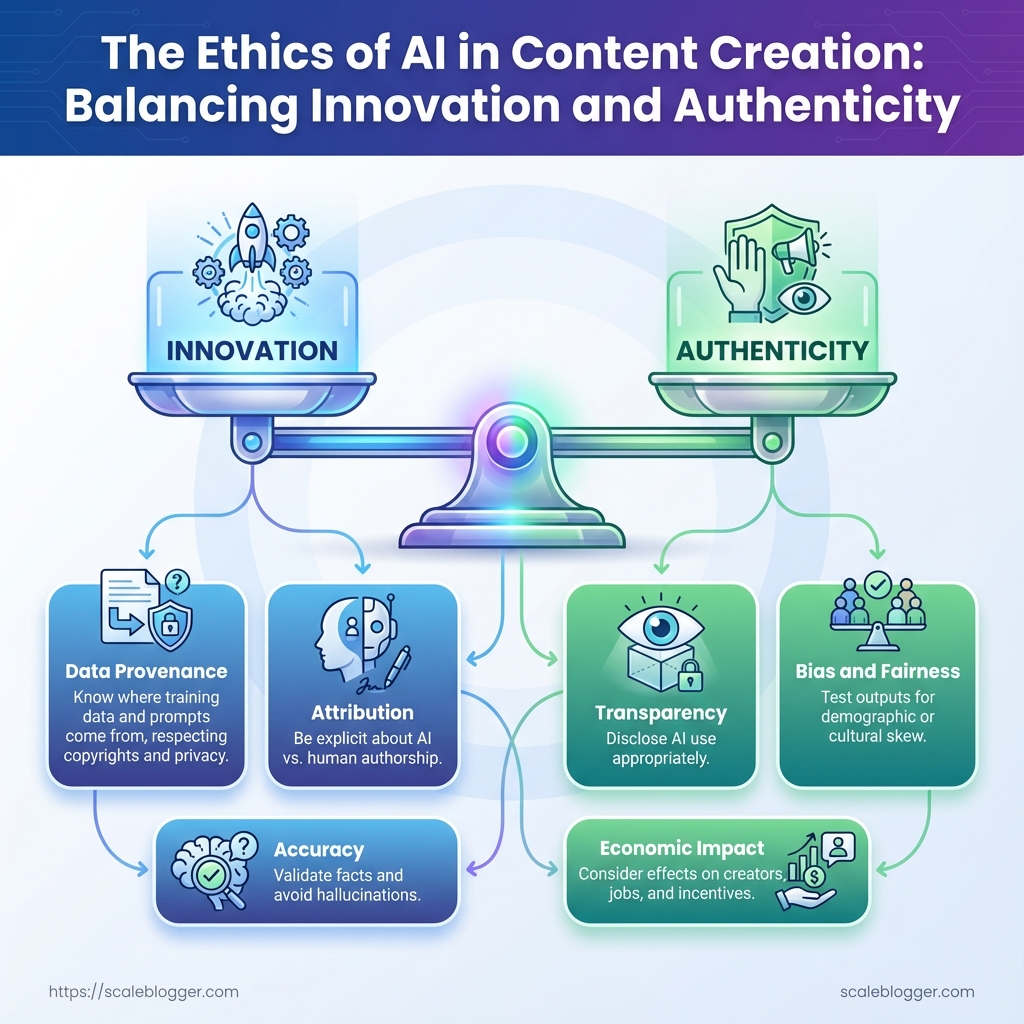
What Is the Ethics of AI in Content Creation?
AI ethics in content creation means applying principles and practices that make AI-generated writing honest, fair, and responsible across the whole content lifecycle. At its simplest: it’s about ensuring tools and workflows produce content that readers can trust and that creators can defend.
Definition: AI ethics in content creation = principles and practices ensuring AI-generated content is honest, fair, and responsible.
Scope: This covers data sources, attribution, truthfulness, bias mitigation, transparency, consent, and downstream impact on audiences and creators.
Think of ethics as traffic rules for content creation: they don’t slow progress for the sake of it — they prevent collisions, make the journey predictable, and let more people reach their destination safely. That analogy resurfaces whenever choices about data, attribution, or amplification come up.
Core dimensions to watch
- Data provenance: Know where training data and prompts come from and whether use respects copyrights and privacy.
- Attribution: Be explicit about what was generated by
modelversus human-authored input. - Accuracy: Validate facts and avoid hallucinations before publishing.
- Bias and fairness: Test outputs for demographic or cultural skew and correct systematic errors.
- Transparency: Disclose AI use in a way appropriate for the audience and industry.
- Economic impact: Consider how automation affects creators, jobs, and incentives.
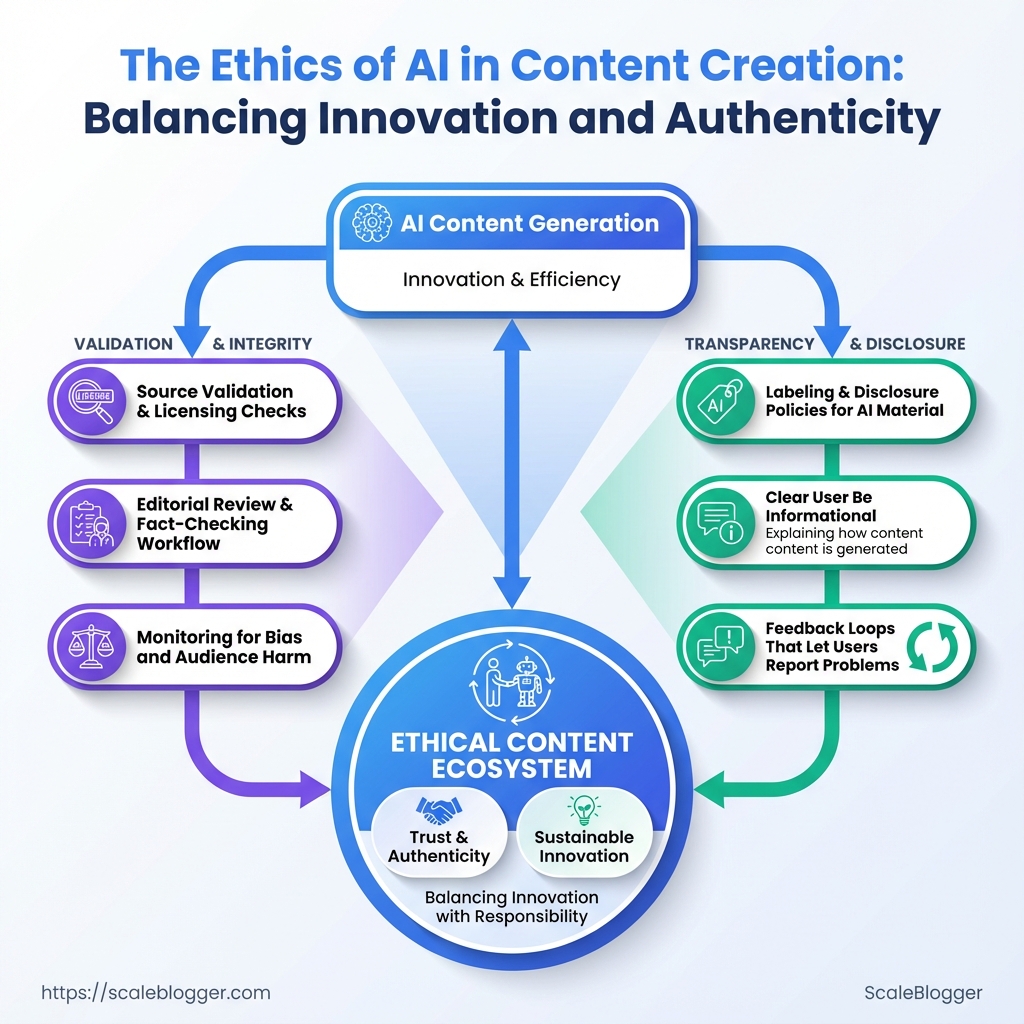
Practical scope checklist
- Source validation and licensing checks
- Editorial review and fact-checking workflow
- Labeling and disclosure policies for AI-generated material
- Monitoring for bias and audience harm
- Feedback loops that let users report problems
make this concrete: a marketing team that uses an AI draft but runs each claim through a fact-checker and adds bylines preserves credibility. A publisher that hides AI use risks reader trust and legal exposure.
Ethics isn’t a one-off compliance box; it’s integrated design. Implementing guardrails—prompt templates that exclude sensitive topics, mandatory human edit passes, or content scoring dashboards—keeps quality high while letting automation scale.
Every ethical rule reduces a risk and preserves long-term audience value. Treating ethics like operational design rather than a slogan makes automated content sustainable and defensible in the real world.
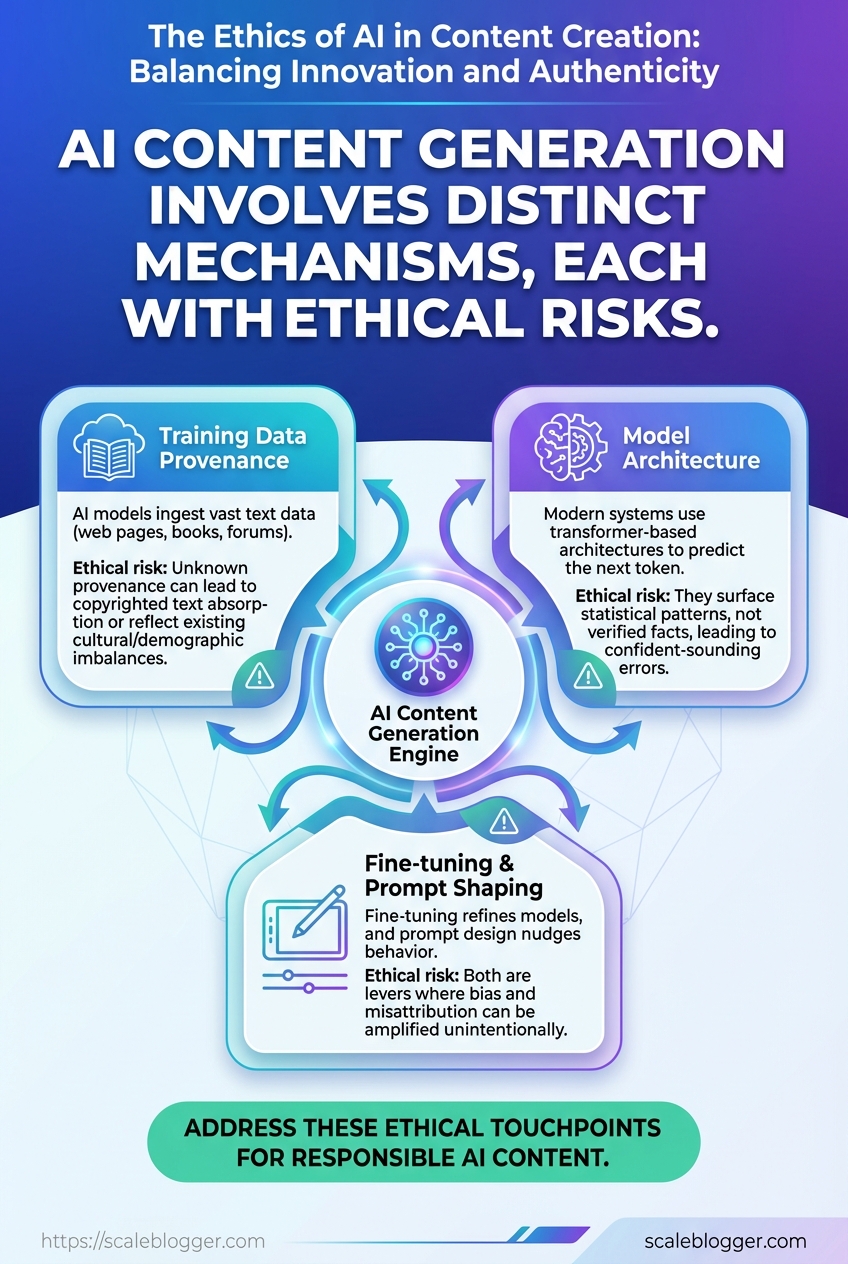
How Does It Work? Mechanisms Behind AI Content and Ethical Risks
AI content systems run on a few predictable mechanics: large models ingest vast text, patterns get compressed into weights, and generation stitches those patterns into new outputs. That compression is powerful for scale but where the ethical questions live — because what goes into the model, how it’s steered, and how it’s published determine whether content is useful, biased, or harmful.
Training data provenance: Training datasets come from crawled web pages, books, forums, and licensed corpora. When provenance is unknown, copyrighted text or niche community language can be absorbed without consent, producing output that reflects existing cultural and demographic imbalances.
Model architecture: Modern systems use transformer-based architectures that predict the next token. That means they surface statistical patterns, not verified facts, which is why confident-sounding errors happen.
Fine-tuning and prompt shaping: Fine-tuning refines a model toward a goal; prompt design nudges behavior at runtime. Both are levers for quality but also points where bias and misattribution can be amplified.
What follows are concrete mechanisms and where ethics typically surface.
- Opaque sources: Models lacking source metadata can reproduce misinformation.
- Amplified bias: Underrepresented voices are often mischaracterized by models trained on imbalanced corpora.
- Hallucination: Models fabricate plausible but false claims because generation optimizes for fluency, not truth.
- Authorship drift: Automated pipelines that stitch AI drafts into publishing flows blur who is responsible for content.
- Data intake: Curators collect and filter datasets.
- Pretraining: Models learn statistical patterns across languages.
- Fine-tuning: Teams align behavior to tasks or brand voice.
- Prompting/policy layers: Runtime controls add constraints and safety checks.
- Publishing: Automated pipelines schedule and post content, sometimes without final human sign-off.
Training data provenance: When dataset lineage is visible, it enables fact-checking and legal compliance.
Hallucination: The model generates content that is not grounded in its training or external facts.
Authorship and accountability: Automated workflows complicate who signs off on accuracy and ethical responsibility.
Common AI content mechanisms with associated ethical risks and mitigation strategies
| Mechanism | How it works (simple) | Ethical risk | Practical mitigation |
|---|---|---|---|
| Training data sourcing | Large-scale web crawl + licensed corpora | Copyright issues, dataset bias | Curate datasets, log provenance, use filters |
| Model fine-tuning | Adjust weights on domain data | Overfitting, niche bias | Diverse fine-tuning sets, audits, validation sets |
| Prompt engineering | Craft inputs to steer output | Reinforces framing bias | Standardized prompts, red-team testing |
| Automated publishing pipelines | AI outputs auto-scheduled to CMS | Reduced human review, accountability gaps | Mandatory human review gates, edit logs |
| Synthetic media generation | AI creates realistic images/audio | Deepfakes, identity misuse | Watermarking, provenance metadata, consent checks |
Key insight: The same levers that make AI content efficient are where risk concentrates — data lineage, alignment choices, and deployment automation. Addressing those three keeps content authentic and defensible.
For teams building production pipelines, integrate provenance tracking, add human review checkpoints, and include bias audits as routine. Tools that automate these controls—whether internal workflows or platforms like Scaleblogger.com for content automation—help balance scale with ethical responsibility. Guardrails aren’t optional; they’re how AI content becomes trustworthy and useful.
Why It Matters: Business, Legal, and Audience Implications
AI-driven content choices change more than editorial calendars; they reshape trust, search visibility, and legal risk in ways that map directly to business outcomes. When readers doubt a brand’s authenticity, conversion rates drop and churn rises. When search engines can’t clearly attribute expertise or originality to a page, rankings slip. When legal obligations like copyright and disclosure are ignored, liability and brand damage follow. Treating ethics and authenticity as operational levers rather than abstract ideals turns them into measurable KPIs.
Business impacts
- Revenue and conversion: Consumers who perceive content as authentic engage longer and convert at higher rates; content that feels automated often underperforms.
- Brand equity: Consistent, transparent attribution and sourcing strengthens reputation and reduces negative PR risk.
- Operational efficiency: Automating safe-guarded content processes — review checklists, version control, content scoring — scales output without sacrificing integrity.
SEO implications
- Search signals depend on credibility. Algorithms reward demonstrable expertise and originality; use
E-E-A-Tprinciples to shape content briefs and metadata. - Duplicate or low-value AI-generated content can trigger ranking penalties or deprioritization by search engines.
- Topical authority matters: Building coherent clusters and internal linking demonstrates subject mastery to both users and search bots.
Legal and compliance areas to watch
- Copyright: AI can inadvertently reproduce protected text or images. Monitor for verbatim matches and maintain permissions records.
- Disclosure obligations: Sponsored content or heavily AI-assisted pieces often require clear disclosure under advertising standards.
- Privacy and data use: If training data includes personal data, document consent and retention policies.
Content authenticity: Use verifiable sourcing, author attribution, and editorial notes where AI was used.
AI ethics: Establish guardrails for bias, fairness, and explainability.
Compliance monitoring: Track provenance and red-line content types.
- Define monitoring metrics: set baseline traffic, engagement, and trust signals.
- Instrument detection: add plagiarism checks, originality scoring, and manual review flags.
- Close the loop: route flagged items for remediation and log outcomes.
Practical example: a publisher added an originality score to their CMS and removed pieces scoring below threshold; organic traffic recovered within weeks as flagged content was rewritten and properly cited.
Integrating ethics into content ops reduces legal surprises, protects rankings, and preserves reader trust. Treating these issues as measurable processes—complete with thresholds, automated checks, and escalation paths—pays back in clearer search performance and fewer compliance headaches.
Common Misconceptions About AI-Generated Content
AI content isn’t magic that replaces human judgment; it’s a tool that amplifies workflow when used correctly. Quality problems usually come from unclear prompts, poor data, or skipping human review—not from the model itself. Below are the most persistent myths, why they’re misleading, the real risks if teams believe them, and practical policies to adopt instead.
Side-by-side comparison of common myths, why they’re misleading, and recommended practical policies
| Myth | Why it’s misleading | Risks if believed | Recommended practice |
|---|---|---|---|
| AI replaces human authors | AI automates certain tasks but lacks domain judgment, nuanced storytelling, and ethical reasoning | Content loses brand voice; strategic thinking and investigative reporting suffer | Require human editorial oversight and retain writers for strategy, nuance, and interviews |
| AI-generated content doesn’t need editing | Raw outputs often contain factual errors, awkward phrasing, or hallucinations | Misinformation, reputation damage, and SEO penalties from low-quality pages | Implement a two-step process: edit + fact-check before publishing |
| Disclosure will reduce engagement | Transparency can build trust; audiences appreciate honesty about methods when value is clear | Loss of trust if discovered later; legal exposure in regulated topics | Add clear disclosure and explain how human review improves results |
| All AI outputs are biased | Models reflect training data; bias is real but not universal or uniform | Overcorrecting can censor valid perspectives; ignoring bias harms credibility | Use bias-check workflows and diverse reviewer panels for sensitive topics |
| Copyright isn’t an issue with AI | Models may reproduce training data patterns; IP risk depends on model and use case | Legal disputes, DMCA takedowns, and blocked publishers | Track sources, avoid verbatim reproduction, and use licensed datasets or models with clear terms |
Industry practice shows the gap between expectation and reality comes down to process, not technology. Build simple guardrails — editorial checklists, bias filters, and source-tracing — and most concerns become manageable. Teams that adopt human-in-the-loop workflows scale faster and avoid common pitfalls.
Practical pointers: Start small: pilot AI for research briefs before full drafts. Add checks: require citations for factual claims and run a plain-language bias review. * Measure impact: track engagement and accuracy, not just output volume.
If the goal is consistent, discoverable content, combining human editorial standards with AI-powered SEO tools speeds delivery without sacrificing trust. Use AI to amplify judgment, not to replace it.
Real-World Examples: Case Studies and Use Cases
AI-driven content pipelines can be practical and measurable — not just experimental toys. Below are grounded examples from journalism, SEO marketing, e-commerce, and creator monetization that show what worked, what failed, and clear first steps to apply the lesson.
Journalism — Local newsroom automation What went right: A regional newsroom used AI to generate data-driven beats (crime logs, budget reports) and freed reporters for investigative work. Automation handled repetitive summarization and data extraction from public records. What went wrong: Over-reliance on templates produced stale phrasing and occasional factual mismatches when source schemas changed. Action item: Pilot automation on one beat, pair each automated draft with a human fact-checker for the first 60 days.
SEO marketing — Topic cluster scale-up What went right: An agency used semantic topic mapping and content scoring to create tightly linked topic clusters; organic traffic rose as search intent coverage improved. What went wrong: Publishing speed outpaced editorial standards, causing thin pages that cannibalized ranking. Action item: Introduce a minimum content-quality gate (read time + usability checklist) before publishing.
E-commerce — Product page personalization What went right: Automated generation of long-form product descriptions plus dynamic FAQ sections increased conversion on long-tail SKUs. What went wrong: Generic tone eroded brand distinctiveness and returned higher returns for some items. Action item: Implement a brand-voice layer and A/B test personalized vs. branded descriptions.
Creator monetization — Newsletter + course funnel What went right: Creators used AI to repurpose existing posts into a paid newsletter and micro-course, cutting production time and raising subscriber LTV. What went wrong: Over-automation of newsletters reduced perceived authenticity, triggering unsubscribes. Action item: Reserve one organic, unautomated piece per week to preserve voice and trust.
Mid-market publisher — Performance benchmarking What went right: Combining automation with performance analytics flagged underperforming topics, enabling targeted refresh campaigns. What went wrong: Blind reliance on historical metrics delayed response to a sudden topical trend. Action item: Blend trend signals with historical benchmarks and allocate a reactive editorial budget.
Practical checklist worth adding: start small, measure engagement, keep humans in the loop, and lock brand voice into templates. For teams ready to scale those processes, tools that automate the pipeline and track performance make the difference between chaos and predictable growth, and platforms like Scaleblogger.com can help build that bridge from idea to measurable traffic.
These examples show how the right balance of automation and editorial control creates reliable gains — and where shortcuts quickly erode value.
📥 Download: Ethical AI Content Creation Checklist (PDF)
Best Practices & Policy Checklist for Ethical AI Content
Start with clear rules baked into workflow: label AI-assisted content, require human editing, track training data sources, and run bias/factuality checks before publishing. Policies that live in everyday tools and roles stop edge-case failures from becoming reputation problems. Below are practical policies mapped to owners and tools, followed by a prioritized 10-step implementation checklist and a short disclosure template you can drop into content.
Map policy/action items to owner and recommended tool types
| Policy/Action | Owner (role) | Recommended tools | Priority (1-3) |
|---|---|---|---|
| AI disclosure & labeling | Content Owner / Editor | Grammarly for grammar + custom CMS label | 1 |
| Human-in-the-loop editing | Senior Editor | CMS editorial workflow, track changes, editorial dashboard |
1 |
| Training data provenance checks | Data Steward | Hugging Face Hub, internal data catalog, version-control |
2 |
| Bias auditing | ML Ethics Lead | IBM AI Fairness 360, Fairlearn, model cards | 2 |
| Plagiarism & factuality checks | Fact-checker / Editor | Copyleaks, Turnitin, OpenAI fact-check prompts | 1 |
Key insight: The highest-priority items are disclosure and human editing—these are low-friction, high-impact controls. Mid-priority items (data provenance, bias auditing) require technical ownership but prevent systemic issues. Tool recommendations mix editorial, ML, and verification capabilities so teams have practical plug-and-play options.
- Assign policy sponsors: designate a single Policy Owner and a cross-functional review team.
- Create an AI content label standard: define when content gets
AI-assistedvsAI-generatedtags. - Implement a mandatory human review step before publishing; assign Senior Editor sign-off.
- Record dataset provenance for any custom models; assign Data Steward to maintain records.
- Run bias checks on model outputs for sensitive topics; log findings with the ML Ethics Lead.
- Integrate plagiarism and factuality scanners into the CMS workflow; assign Fact-checker.
- Maintain versioned model cards and changelogs; ML Ops owns updates and rollbacks.
- Set periodic audits: quarterly policy review and incident post-mortems owned by Head of Content.
- Train staff on policy and tooling with certified onboarding sessions; People Ops manages training.
- Public transparency: publish an accessible AI use policy and a contact for concerns; Legal/Communications owns this.
Disclosure template (short):
This piece was produced with the assistance of AI tools and edited by our editorial team to ensure accuracy and original reporting. For details about our AI use, visit our policy page.
Practical policies and a living checklist reduce risk and keep content credible. When ownership, tooling, and disclosure are explicit, teams move faster with fewer surprises — and readers notice the difference.
Conclusion
This feels like a practical moment: AI can speed drafts and spark innovative content, but it also forces choices about voice, transparency, and trust. The article showed how simple fixes — adding attributions, setting guardrails in prompts, and running human edits — restore content authenticity and reduce legal exposure. For teams wondering how to preserve a writer’s voice or whether a regulatory audit will flag their work, start by mapping where automation touches judgment and then add human checkpoints. Adopt clear attribution practices, build a lightweight review workflow, and measure audience trust, and those three changes will change how readers experience your output.
For teams ready to move from theory to practice, take one concrete next step: pilot a single workflow (drafting → editor review → publish) and track quality and engagement for four weeks. To streamline this process, platforms like Learn how Scaleblogger helps teams deploy AI responsibly can help automate audits, manage prompts, and keep content aligned with brand standards. If the immediate questions are “How much human oversight is enough?” or “Which metrics show authenticity improvements?”, focus on author bylines, engagement lift, and a sample of reader feedback — those signals tell the story quickly.
