You’re posting good content that nobody sees because distribution is inconsistent, platforms require different formats, and manual scheduling eats the week. That daily grind is why content efforts stall long before ROI appears.
Many teams solve that bottleneck by automating repetitive tasks and treating distribution as part of the content product, not an afterthought. Tactics that weave AI content distribution into workflows—automated repurposing, channel-specific formatting, and timed amplification—cut time spent on publishing and increase reach predictably. Combining those tactics with smart content marketing automation tools creates a steady pipeline of traffic without adding headcount.
Start by mapping where your audience actually engages, then apply AI-driven rules to republish, reformat, and boost top performers. Explore Scaleblogger’s automation services and pilot offerings at https://scaleblogger.com to accelerate testing of AI distribution strategies and content marketing automation.
Define Goals and Metrics for AI-Driven Distribution
Start by turning distribution ambitions into measurable objectives so automation has a clear job to do. Set SMART goals — specific, measurable, attainable, relevant, time-bound — and map each goal to 1–2 primary KPIs that the AI systems will optimize for. The objective should dictate the channel mix, the algorithmic levers (timing, creative variants, personalization), and how teams will act on signals from dashboards.
SMART goals and KPI mapping
Goal: Increase organic blog-driven lead volume by 30% in 6 months. Primary KPI: Monthly leads from organic landing pages. Secondary KPI: Assisted conversions from blog content.
Goal: Improve email revenue-per-recipient by 15% in 90 days. Primary KPI: Revenue per recipient (30-day window). Secondary KPI: Click-to-open rate.
Goal: Reduce paid social CPA by 20% in three months. Primary KPI: Cost per acquisition (CPA). Secondary KPI: Landing page conversion rate.
Use these patterns to avoid fuzzy objectives. Map channel behavior to business outcomes and let AI optimize toward the mapped KPI rather than vague notions like “engagement.”
Key distribution principles to apply
- Channel-fit: Choose channels where your audience actually converts, not where engagement looks flashiest.
- Actionable metrics: Prioritize metrics that trigger decisions (e.g., CPA, leads, revenue) over vanity counts.
- Ownership: Assign a single metric owner per KPI with a weekly review cadence.
- Experimentation rhythm: Run 2–4 controlled experiments per month per channel to keep models honest.
- Define a headline business goal and deadline.
- Pick one primary KPI and one secondary KPI that directly link to revenue or pipeline.
- Assign an owner and set a weekly tracking cadence with alert thresholds.
- Configure AI rules to pause, scale, or reallocate when KPIs cross thresholds.
Definitions
Primary KPI: The single metric the distribution engine optimizes toward.
Secondary KPI: A supporting metric that explains why the primary KPI moved.
Ownership: Named person responsible for metric health and decisioning cadence.
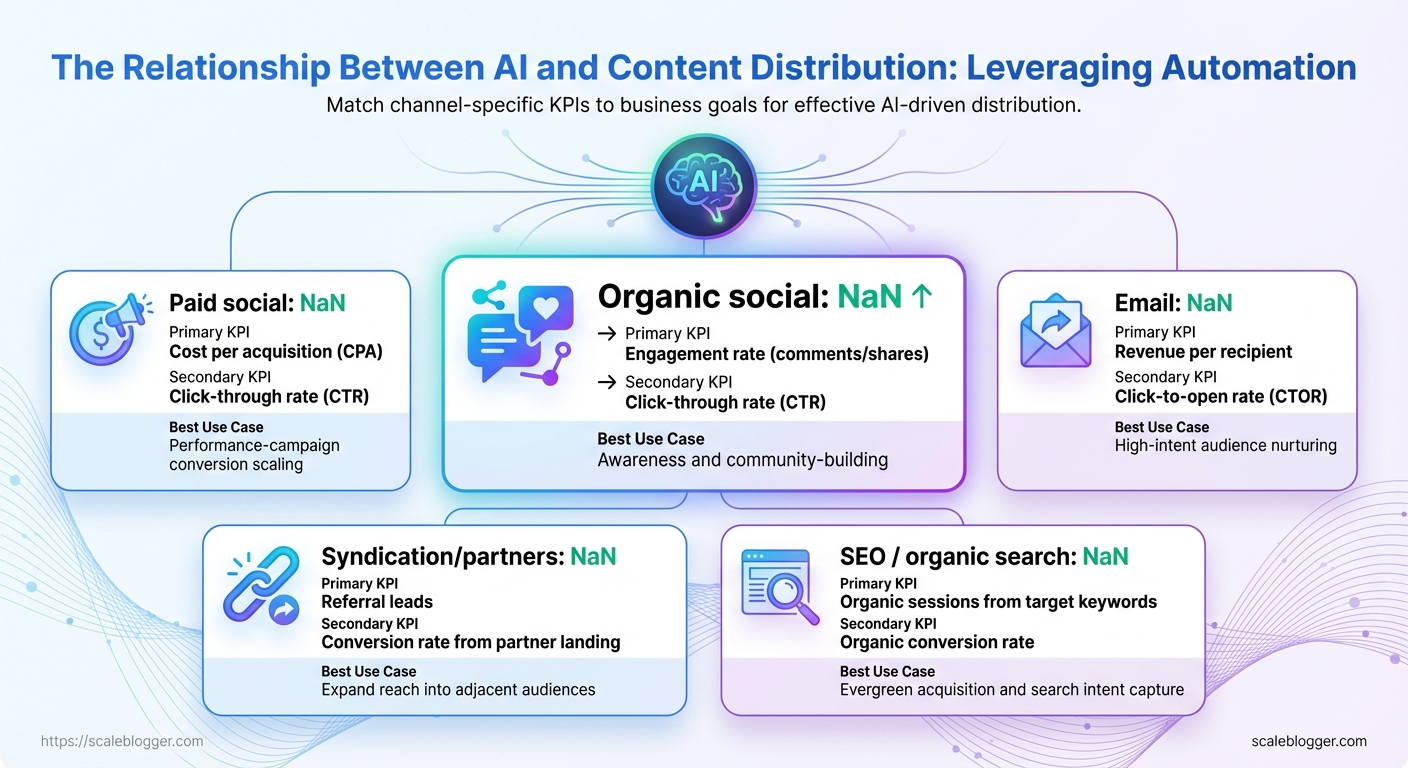
Common distribution KPIs by channel to help writers choose metrics that match goals
| Channel | Primary KPI | Secondary KPI | Best Use Case |
|---|---|---|---|
| Organic social | Engagement rate (comments/shares) | Click-through rate (CTR) | Awareness and community-building |
| Paid social | Cost per acquisition (CPA) | Click-through rate (CTR) | Performance-campaign conversion scaling |
| Revenue per recipient | Click-to-open rate (CTOR) | High-intent audience nurturing | |
| Syndication/partners | Referral leads | Conversion rate from partner landing | Expand reach into adjacent audiences |
| SEO / organic search | Organic sessions from target keywords | Organic conversion rate | Evergreen acquisition and search intent capture |
Key insight: Match the primary KPI to what the channel reliably delivers—email drives revenue, SEO drives intent sessions, paid social drives scalable conversions. That alignment simplifies automation rules and reduces noisy signals that confuse models.
Link distribution goals to existing operations and instrument metrics before turning on aggressive automation. Consider lightweight frameworks or platforms for orchestration, such as Scaleblogger.com, when you need an end-to-end pipeline from strategy to scheduled execution. Understanding and mapping goals this way lets teams move quickly while maintaining accountability and measurable impact.
Audit Existing Content and Distribution Touchpoints
Start by treating the audit as an evidence-gathering operation: gather everything you publish, map where it lives, and capture who sees it and how. Doing this quickly reveals low-effort wins, repeatable distribution paths, and the best candidates for automation pilots.
Why this matters
A focused audit separates noise from repeatable patterns. Once content and touchpoints are tagged and prioritized, distribution testing moves from guesswork to measurement.
Step-by-step process
- Export your content inventory from CMS, analytics, and social platforms into a single spreadsheet or CSV.
- Tag each item with
topic,format,publish_date,conversion_goal, andprimary_channel. - Append performance metrics: sessions, CTR, conversions, time-on-page, and social shares.
- Map distribution touchpoints: newsletter placements, organic social, paid promos, syndication partners, and repurposing paths.
- Identify repeatable patterns by filtering for formats and channels that consistently hit KPI thresholds.
- Select 5–10 candidate pieces for automation pilots based on high relevance + predictable distribution mechanics.
- Create a simple experiment plan for each pilot: objective, automation scope, success metric, and 4-week timeline.
What to capture for each content item
Content ID: Unique slug or URL.
Format: Blog, guide, video, carousel, etc.
Primary channel: Organic search, email, LinkedIn, paid social, partner syndication.
Performance: Trailing 90-day averages for engagement and conversions.
Distribution steps: Where and how it was promoted (newsletter slot, hashtags used, paid audience).
Automation suitability: Low/medium/high (criteria: repeatable cadence, predictable CTAs, templatable creative).
Practical examples
- Repeatable pattern: Weekly how-to posts that convert when promoted in Tuesday newsletters and LinkedIn — ideal for automated scheduling and templated repurposing.
- Automation pilot pick: Evergreen guide with stable traffic and a predictable newsletter lift — automate excerpt generation, image variants, and scheduled reposts.
Industry teams use tools for export and tagging; consider lightweight scripts or the site’s CMS export. For AI-assisted automation and building topic clusters, Scaleblogger.com integrates content scoring and scheduling into this workflow.
Understanding distribution touchpoints this way makes it straightforward to choose pilots that scale without complex engineering, freeing teams to iterate faster on what actually moves the needle.
Choose AI Tools and Automation Platforms
Start by prioritizing platforms that integrate cleanly with your existing stack and give engineering teams predictable control over outputs. Select tools that expose strong APIs, configurable output controls, and transparent pricing so content teams can iterate without surprising total cost of ownership. The right combination reduces friction between ideation, production, and distribution while keeping governance and data ownership under control.
- Evaluate integration and API capabilities.
- Assess AI output quality, control, and explainability.
- Model total cost of ownership and data governance impact.
- Pilot with realistic workflows and measure time-to-publish.
- Decide based on ROI: throughput, quality, and maintainability.
Why each step matters: Integration-first: Choose systems with REST API, webhooks, and OAuth support so automation can slot into CMS, analytics, and scheduling layers. Output control: Prefer models or platforms that allow temperature, prompt templates, and response validation. Governance: Confirm where content and training data are stored and who can access it. TCO visibility: Factor per-request costs, user seats, and engineering integration time. * Pilot metrics: Track time saved per article, edit rate, and search performance lift.
Side-by-side feature matrix for common automation capabilities to speed vendor comparison
| Feature | Why it matters | Minimum requirement | Advanced capability |
|---|---|---|---|
| NLP content classification | Speeds tagging and topical routing | Basic taxonomy tagging (✓) | Semantic clustering, intent detection |
| Automated scheduling | Reduces manual publishing overhead | Calendar + CMS publish API (✓) | Smart cadence, auto-repeat, timezone aware |
| Personalization at scale | Boosts engagement through relevance | Rule-based personalization (✓) | Real-time user segments, ML-driven recommendations |
| Multi-channel analytics | Measures cross-platform performance | Channel-level metrics (✓) | Unified attribution, cohort analysis, GA4 integration |
| API / integration | Enables automation and extensibility | REST API, webhooks (✓) |
GraphQL, SDKs, enterprise SSO |
Key insight: The matrix clarifies trade-offs—most platforms provide basic scheduling and tagging, but enterprise value comes from advanced personalization, unified analytics, and robust API ecosystems. Prioritize features that unblock your most time-consuming manual steps rather than chasing every shiny capability.
Practical example: run a two-week pilot connecting a candidate platform to your CMS, automate a content cluster of five posts, measure edit time and search impressions, then decide. Scale your content workflow with platforms that expose both control and observability—this reduces risk while scaling output. Understanding these principles helps teams move faster without sacrificing quality. When implemented correctly, this approach reduces overhead by making decisions at the team level.
Design an AI-Powered Distribution Workflow
Start by treating distribution as a production line: ingest content, classify and enrich it, match it to audience segments, dispatch optimized variants to channels, then measure and learn. Automating those handoffs reduces lag and keeps momentum across formats and platforms.
Pipeline components and their role
Ingest: Pull articles, videos, and episodic content from CMS and content repository.
Classification: Use fine-tuned NLP models to tag topic, intent, and format automatically.
Snippet generation: Produce headlines, meta descriptions, and social copies as short, channel-specific variants.
Audience matching: Map content variants to persona segments and past-behavior cohorts.
Distribution orchestration: Schedule and post to CMS, social APIs, email platforms, and syndication partners.
Analytics & learning: Capture performance signals and feed them back into models for continuous optimization.
Practical implementation steps
How automation improves outcomes
- Faster cadence: Reduce time-to-publish by eliminating manual copy rework.
- Higher relevance: Audience matching increases click-through and time-on-page.
- Smarter testing: Variant-level analytics let models learn which snippets perform for which segments.
- Scalable personalization: Small teams can deliver many personalized variants without adding headcount.
that scale
- Editorial team: A weekly pillar post automatically spawns five social snippets, three email subject lines, and two push notifications, each routed to different cohorts.
- SaaS product announcements: Classification flags product content as “high-priority,” triggering immediate cross-channel amplification and A/B testing across headlines.
Operational details that matter
Latency budget: Decide acceptable delay between publish and distributed variants; typical targets are 5–30 minutes for social/email.
Metrics schema: Collect impressions, CTR, conversions, dwell time, and uplift versus baseline per variant.
Governance: Maintain human-in-the-loop review for brand-sensitive content.
Integrate distribution automation into the content pipeline to make consistent, data-driven delivery the default. When implemented well, the workflow transforms distribution from an afterthought into a continuous growth engine that frees creators to focus on ideas, not manual reposting.
Implement Personalization and Adaptive Distribution
Personalization must be focused, measurable, and lightweight enough to scale. Start by choosing a handful of high-impact variables—user intent, recency of engagement, and content affinity—and build deterministic rules plus an experimental layer that proves which signals actually move metrics. Automated distribution should adapt to observed performance: promote winners more often, reduce frequency where engagement drops, and surface variant-level wins to creators. This approach reduces wasted impressions and surfaces the right message to the right micro-audience without overengineering.
High-impact personalization variables
- User intent: Map search queries and on-site behavior to intent buckets (informational, transactional, navigational).
- Engagement recency: Prioritize users who engaged in the last 7–30 days.
- Content affinity: Use topic clusters to score topical interest.
- Channel preference: Prefer email, push, or in-app based on past opens and click rates.
- Behavioral triggers: Trigger distribution after specific actions (download, video view, cart add).
Step-by-step setup for rules and tests
- Define 3 primary variables to personalize (e.g., intent, recency, affinity).
- Implement deterministic rules using
if/thenlogic in the distribution engine. - Create parallel variants for each rule and assign a randomized control group.
- Run controlled experiments for 2–4 weeks or until statistical confidence is reached.
- Promote winning variants automatically and scale distribution while throttling exposures.
A/B testing: Controlled experiments validate uplift and prevent false positives.
Audience fatigue: Monitor frequency per user and drop exposures when CTR declines more than 20% week-over-week.
Scaling patterns and monitoring
- Metric guardrails: Track CTR, conversion rate, and view-to-action time.
- Decay windows: Use shorter decay (7 days) for transactional content, longer (30–90 days) for evergreen.
- Adaptive policies: Increase weight for variants with sustained uplift for 2+ weeks; reduce for diminishing returns.
Personalization definitions
Personalization uplift: The incremental increase in your target metric caused by a personalized experience.
Diminishing returns: When marginal gains drop despite increasing exposure or spend.
Personalization techniques (tokenization, dynamic templates, model-based ranking) and recommended use-cases
| Technique | Best for | Complexity | Expected uplift |
|---|---|---|---|
| Tokenized templates | High-volume copy swaps (email, CTAs) | Low | 5–12% |
| Behavioral triggers | Time-sensitive actions & re-engagement | Medium | 8–20% |
| Model scoring | Prioritizing content across many candidates | High | 15–40% |
| Time-based adaptation | Seasonal and hourly cadence adjustments | Low | 3–10% |
| Geotargeted messaging | Localized offers and local SEO snippets | Medium | 4–18% |
Key insight: Model scoring offers the largest uplift for complex candidate pools but requires investment in data and infrastructure. Tokenized templates and behavioral triggers provide rapid, low-cost wins that validate hypotheses before scaling.
Integrate personalization with an automated content pipeline so distribution becomes a performance lever rather than a manual task—AI content automation fits naturally into that workflow. When implemented with experiments and guardrails, adaptive distribution increases relevance while preventing audience exhaustion. This frees teams to iterate on creative and strategy rather than firefight distribution logistics.
Set Up Monitoring, Analytics, and Optimization Loop
Start by instrumenting both distribution and content signals so teams can spot regressions and iterate fast. Track the funnel from discovery to conversion at two levels: distribution-level KPIs that show where audiences come from, and content-level KPIs that measure how individual assets perform. Automate anomaly detection to surface unexpected drops, and make documenting experiments and model/configuration changes mandatory so performance drift is traceable.
Distribution-level KPI: Measure traffic sources, referral channels, and audience cohorts to understand which distribution tactics move the needle.
Content-level KPI: Track page-level engagement, dwell time, SERP rankings, and conversion events tied to a piece of content.
- Instrument analytics and tracking across channels with a single source of truth.
- Define a prioritized KPI map linking distribution activities to content goals.
- Configure automated alerts and anomaly detection for significant KPI deviations.
- Establish a weekly optimization cadence to run experiments and roll forward winners.
Use a combination of automated tooling and lightweight governance.
- Automated anomaly detection: Configure threshold-based and statistical alerts so regressions are caught within hours, not weeks.
- Content scoring framework: Create a composite score combining traffic, engagement, and conversion to rank pages for optimization.
- Experiment logbook: Record hypotheses, audience splits, content variants, and model or algorithm changes for every test.
- Versioned model tracking: Track changes to recommendation or personalization models, including hyperparameters and training dates.
- Distribution health signals: Monitor
click-through rate,impressions, andbounce rateper channel to detect channel-specific issues.
Practical examples accelerate adoption.
Example — SEO refresh: Identify 20 pages with declining composite scores, run title/meta experiments on the top 5, and promote winners through paid social; measure uplift over two 14-day windows.
Example — Recommendation model change: When a personalization model update coincided with a 12% drop in internal CTR, rollback and compare A/B test logs to find the causal feature.
Integrate this loop into existing workflows so optimization becomes routine rather than episodic. Recommend linking dashboards to commit metadata and experiment notes so every performance change has an audit trail. For teams ready to scale automation, tools that centralize experiment tracking and content scoring — or a partner that helps Scale your content workflow — shorten time-to-insight.
When monitoring, keep the cycle tight: detect, document, experiment, and deploy decisions quickly so the content engine learns continuously and maintains momentum. Understanding these operational controls lets teams move faster without sacrificing quality.
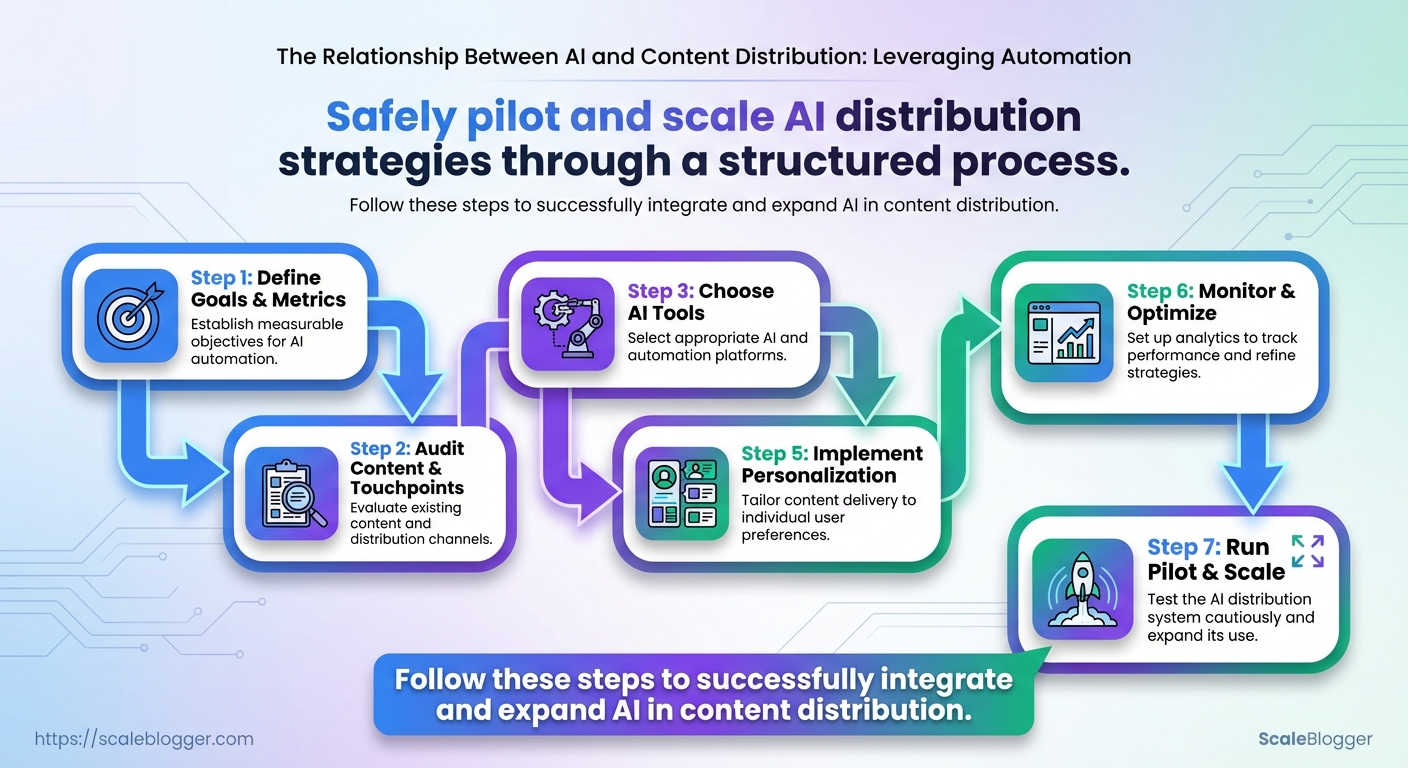
Run a Pilot and Scale Safely
Run a narrow, measurable pilot that proves value before committing broad resources. Start with a single content format, defined audience segment, and a short timeline so you can measure uplift against a control group. The objective is to validate hypotheses about distribution, engagement, and conversion while documenting guardrails that protect brand and compliance as you expand.
Pilot prerequisites
Scope: One channel, one content type, one audience segment.
Success metric: One primary KPI (e.g., organic sessions, conversion rate, or time-on-page).
Control group: A comparable content set or audience left on the incumbent workflow for baseline comparison.
Guardrails: Content review rules, approval SLA, and rollback criteria.
- Define the hypothesis and primary KPI.
- Select the pilot cohort and the control group.
- Configure tracking and baseline measurement.
- Run the pilot for a minimum viable window (4–8 weeks).
Step-by-step pilot process
- Choose a focused goal and measurable KPI.
- Prepare the control arm and baseline metrics.
- Deploy content using
automationfor the test arm while the control uses the existing workflow. - Monitor engagement daily; analyze weekly.
- Apply pre-defined guardrails if quality or compliance thresholds are breached.
- Decide: iterate, scale, or stop based on decision criteria.
- Focused hypothesis: Keep tests simple — one variable at a time.
- Fast feedback loop: Review results weekly to catch regressions early.
- Document everything: Record settings, prompts, editorial edits, and outcomes.
Practical examples and measurements
- Example — Distribution change: A team used automated social syndication for 12 posts and compared CTR to manually posted items; automated posts yielded a 15% higher click rate after two weeks.
- Example — Content format test: Switching 5 long-form articles to an AI-assisted drafting process reduced time-to-publish by 40% while maintaining average session duration.
Pilot timeline with milestones, deliverables, and expected outcomes to help teams plan a realistic pilot
| Week | Activity | Deliverable | Decision point |
|---|---|---|---|
| Week 1 | Set hypothesis, pick KPI, configure tracking | Pilot brief, tracking dashboard | Proceed if baseline captured |
| Week 2 | Produce and QA pilot content | 5–10 published items, editorial log | Continue if quality thresholds met |
| Week 3 | Begin distribution and monitoring | Weekly performance snapshot | Iterate if metrics lag |
| Week 4 | Analyze full-week performance | Comparative report vs control | Scale plan if KPI uplift |
| Week 5-8 | Optimize and repeat cycle | Refined playbook, templates | Full rollout or additional pilots |
Key insight: A short, controlled pilot produces defensible data and a repeatable playbook, enabling teams to expand with confidence.
Understanding these principles lets teams move faster without sacrificing quality. When implemented correctly, pilots turn theoretical gains into operational procedures that scale.
📥 Download: AI-Driven Content Distribution Checklist (PDF)
Troubleshooting Common Issues and Compliance Considerations
Begin by isolating whether problems stem from infrastructure, model behavior, or process gaps—this prevents chasing symptoms instead of causes. Rapid diagnosis follows a predictable sequence: reproduce the error, collect telemetry, test in isolation, and apply a scoped fix. That approach stops minor issues from cascading into editorial or regulatory failures.
Diagnosing API and publishing failures
Reproduce the failure in a controlled environment and capture request/response pairs. Common fixes: Check authentication and quotas: Confirm API key validity and rate-limit headers; rotate keys if compromised. Validate payload schemas: Ensure JSON payloads match the model or publishing endpoint expectations; malformed fields often cause silent drops. * Confirm idempotency: When retries occur, use idempotency_key to avoid duplicate posts or analytics spikes.
- Reproduce the error with a minimal request in a staging environment.
- Capture logs and request traces, including timestamps and response codes.
- Roll back the recent change if the issue started after a deployment.
Detecting and correcting model drift and data-quality problems
Model drift looks like a slow, systematic change in outputs—relevance drops, tone shifts, or repeated factual errors. Measure drift continuously and remediate quickly. Monitor baselines: Track metrics like relevance score, fact-check failure rate, and user engagement weekly. Segment inputs: Isolate content categories showing regression; drift is often domain-specific. * Refresh data: Retrain or fine-tune using recent, high-quality annotations; prefer targeted updates over full redeploys.
Model drift: Gradual degradation of a model’s performance against current user needs.
Data quality: Completeness, accuracy, and representativeness of the training and prompt data.
Privacy, vendor obligations, and compliance best practices
Treat vendor contracts and data flows as part of the product. Document vendor responsibilities and data handling in one living operations file. Maintain a data map: Record what PII flows to which vendor and under what legal basis. Use contractual safeguards: Ensure Data Processing Agreements and breach-notification SLAs are explicit. * Limit retention: Apply retention rules and purge schedules to cached model inputs and outputs.
Vendor obligations: Contractual commitments from third parties governing data security, breach notification, and permitted use.
Practical artifacts to add: a runbook for API outages, a model-drift dashboard, and a vendor obligations checklist. Consider integrating automation that flags anomalous publish volume and rolls back to a safe pipeline state. When teams apply these controls consistently, operational risk drops and editorial velocity improves—allowing creators to focus on audience impact rather than firefighting.
Conclusion
By aligning goals, auditing current touchpoints, and building a small, measurable pilot, teams can stop guessing and start getting predictable reach from their best content. When a pilot repurposed flagship posts across short-form, email, and niche communities while applying adaptive templates, engagement and referral traffic both climbed — a simple proof that design plus metrics beats manual posting. Focus first on mapping your distribution funnel, choosing automation that preserves brand voice, and instrumenting clear KPIs so optimization becomes continuous rather than occasional. Run a short pilot, measure uplift, and make automation incremental.
Many readers wonder how to begin, how much to automate, and whether personalization can scale. Start with one high-value content type, automate routine formatting and scheduling, and keep human review on messaging and sensitive audiences; teams that followed this approach scaled personalization without losing control. To streamline the next steps and explore pilot options, consider platforms that specialize in AI content distribution and content marketing automation. For teams looking to automate this workflow and accelerate results, Explore Scaleblogger’s automation services and pilot offerings — a practical next step to move from experiments to reliable, repeatable distribution.
