Marketers are drowning in a constant feed of articles, posts, and trends while audience attention shrinks.
That mismatch kills reach and makes relevance feel accidental.
That’s where AI-driven content curation steps in.
It acts as AI for content discovery, pairing behavior signals with topic analysis to improve content marketing relevance without relying on guesswork.
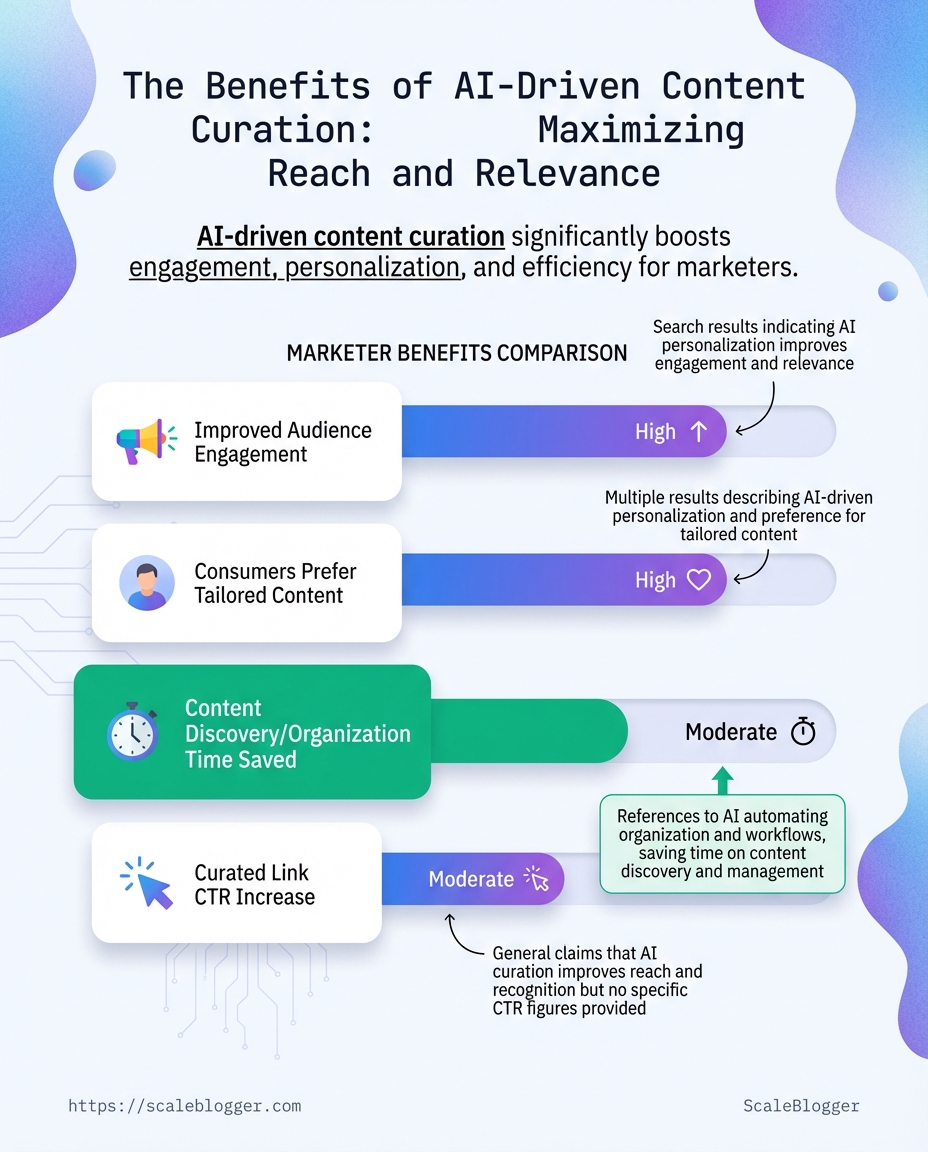
The results are measurable: 80% of marketers reported improved audience engagement rates in 2025.
And 70% of consumers said they prefer content recommendations tailored to their interests in 2025.
Teams also gain efficiency: AI curation can cut content discovery and organization time by up to 30%.
Brands using these tools see click-through rates rise about 15–20% on curated links.
Less time spent hunting content and more time delivering what audiences want translates directly into broader reach and deeper relevance—without inflating headcount.
A common scene: overwhelmed creators, missed opportunity
What if every minute your team spends hunting articles could instead buy attention from an ideal reader? Most content teams feel exactly that pinch. They wake to overflowing tabs, Slack threads about briefs, and an editorial calendar that looks full but underperforms. Daily friction shows up as small leaks.
A writer spends an hour finding a single link.
An editor re-writes headlines to chase trends.
Social posts go out late and generic.
Those tiny inefficiencies add up to missed reach and wasted budget.
This matters because attention is finite and competition is constant.
Manual workflows lose speed, consistency, and personalization — and those are the exact levers that lift content performance.
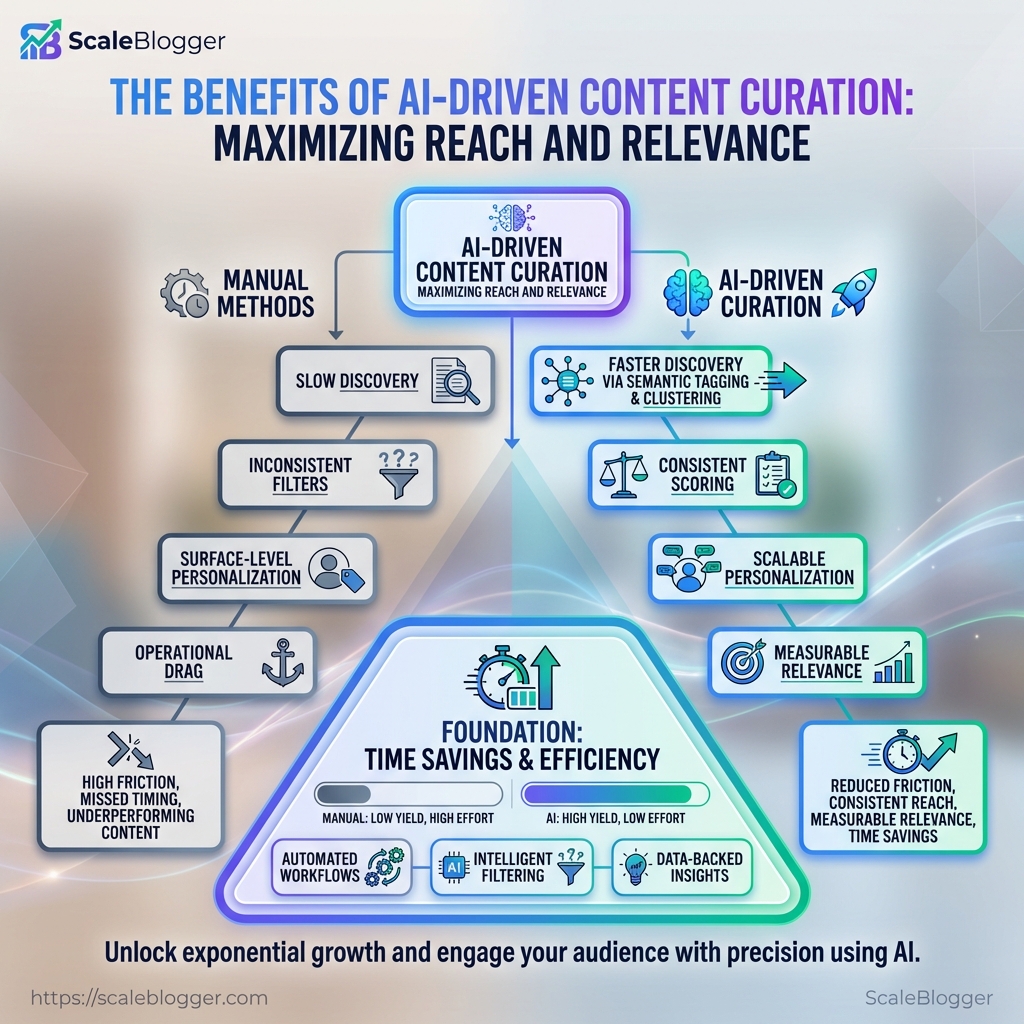
Why manual curation fails at scale Manual curation works when your scope is small.
It breaks down fast once you add more topics, channels, or audience segments.
Slow discovery: Finding niche stories by hand takes time and misses timely angles.
Inconsistent filters: Different editors apply different standards.
That harms brand voice and reliability.
Surface-level personalization: Human curators can tweak for a segment, but they can’t maintain hundreds of micro-personalizations.
Operational drag: Duplicate effort across teams creates wasted cycles and longer publishing lead times.
What AI brings to the table AI content curation removes repetitive work and raises consistency across channels.
It can tag, rank, and match pieces to audience intent in seconds.
AI saves time — studies show up to 30% time savings in curation workflows (2025).
It also improves engagement: 80% of marketers reported better audience engagement after adopting AI-driven curation (2025).
Consumers notice the difference, too — 70% said they prefer recommendations tailored to their interests (2025).
Faster discovery:
semantic taggingand topic clustering surface relevant stories immediately.Consistent scoring: Models apply the same quality rules across sources and authors.
Scalable personalization: Algorithms match content variants to thousands of audience slices.
The diagram contrasts a manual pipeline — inboxes, spreadsheets, human review, delayed publishing — with an AI-driven pipeline that ingests feeds, applies semantic tagging, ranks by relevance, and outputs personalized posts to channels.
It highlights where time and audience relevance increase.
Below the visual, the contrast becomes obvious: manual curation creates friction and missed timing; AI curation converts that friction into consistent reach and measurable relevance, as tools like Curata, Taboola, and Feedly demonstrate in practice.
This scene repeats in agencies and in-house teams. Fixing it means removing busywork so creators can focus on strategy and craft.
Technical foundations: how AI-driven content curation works
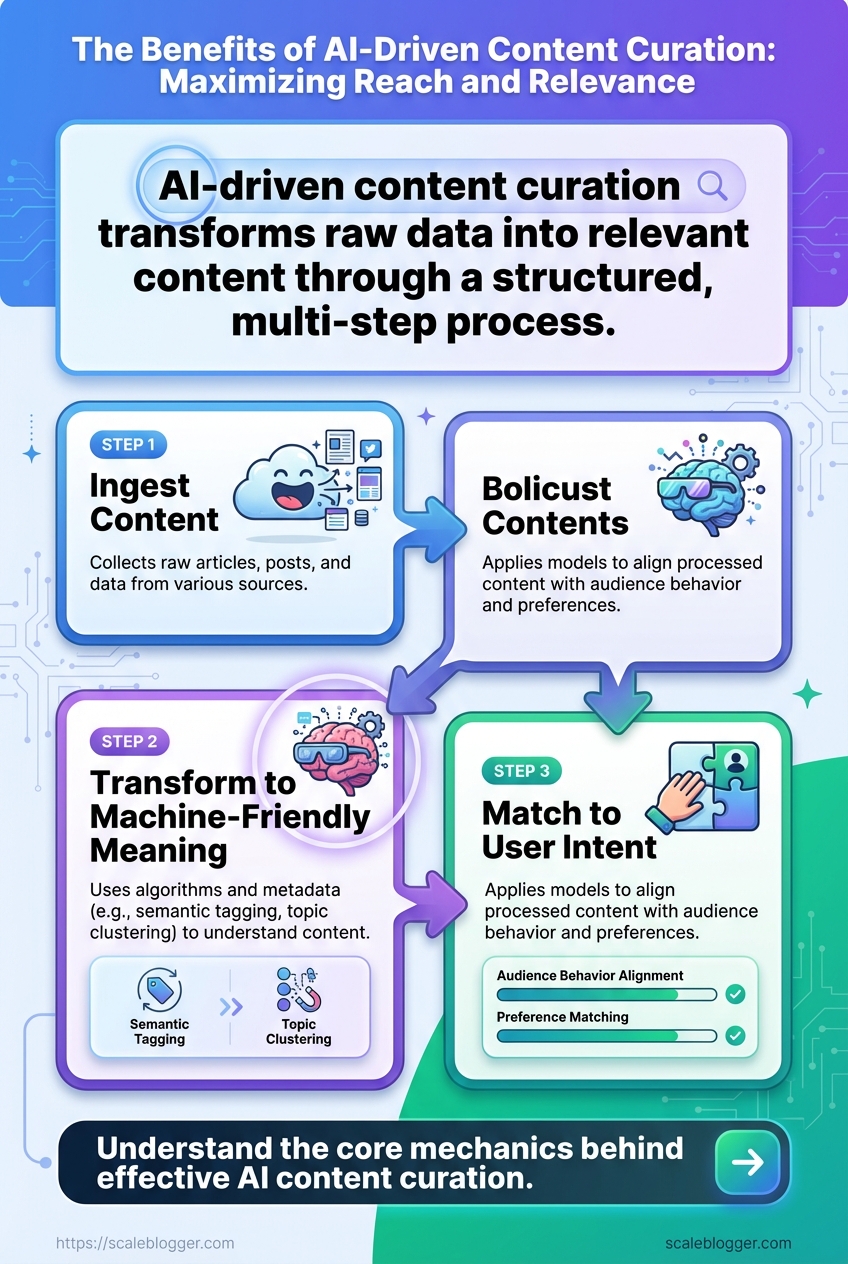
AI-driven content curation converts a mountain of raw articles into a steady flow of relevant, high-value items your audience actually clicks and reads.
At its core it does three things: ingest content, turn text into machine-friendly meaning, and match that meaning to user intent.
When those steps run well, teams save time and see measurable lifts — in 2025, 80% of marketers reported higher audience engagement after adopting AI curation, and many reported up to 30% time savings finding and organizing content.
The mechanics are straightforward but the details matter.
Success depends on the combination of algorithms, metadata, and clean data pipelines rather than any single model.
Tools from the market — think Curata, Feedly (Leo), and Taboola — implement variants of this stack to surface content at scale, and real-world deployments often pair several methods to hit different goals.
Below I unpack the stack: what each layer does, which models run there, and the engineering trade-offs that determine whether recommendations feel eerily relevant or just noisy.
Core components: ingestion, semantic analysis, metadata enrichment
Start with ingestion.
Every pipeline must collect sources, normalize formats, and deduplicate content.
Without that, downstream models learn garbage.
Content ingestion: Collect feeds, RSS, APIs, and web scrapes; normalize to a common schema and store raw and cleaned text.
Semantic analysis: Convert text into meaning using
embeddings, named-entity extraction, and sentiment tagging so content can be compared by idea, not just keywords.Metadata enrichment: Add fields like topic tags, recency score, author authority, and predicted audience intent to make matching and filtering precise.
Models and methods: embeddings, topic modeling, recommendation engines
Embeddings are the backbone.
They map sentences and articles into vectors so similarity becomes a distance measurement.
Use models fine-tuned on your vertical content for best results.
Topic modeling (LDA or neural topic models) helps cluster content into human-readable themes.
That supports editorial workflows and prevents repetitive recommendations.
Recommendation engines combine signals.
Collaborative filters, content-based similarity, and learning-to-rank models sit together.
In practice, hybrid systems outperform pure collaborative or pure content approaches, producing the 15–20% click-through uplift many brands reported in 2025.
Data requirements and engineering considerations
Quality beats quantity.
Curated, labeled examples and consistent timestamps matter more than an order of magnitude more documents.
Ensure a single source of truth for content metadata, with versioning and schema validation.
Log user interactions (clicks, dwell time, shares) and feed them back into retraining loops for
onlineand batch updates.Monitor bias and drift: track freshness, topic coverage, and cold-start failure modes, and roll back or retrain when metrics degrade.
This short walkthrough shows a sample data flow, model choices, and evaluation metrics you should monitor when building a recommendation pipeline.
Watch it to see a concrete pipeline diagram and code-level examples.
AI curation is an engineering problem as much as a modeling one.
Nail the data plumbing, choose the right mix of models, and the recommendations stop being guesswork and start driving real engagement.
Tangible benefits for reach and relevance
What if more of your content reached the right people, not just more people? AI-driven content curation makes that shift measurable: it raises discovery by matching content to individual intent, lifts engagement by surfacing the right format at the right time, and frees hours that teams can spend on strategy instead of busywork.
Marketers who adopted AI curation reported clear gains.
In 2025, 80% of marketers said AI-driven curation improved audience engagement, and 70% of consumers said they prefer recommendations tailored to their interests (2025).
Brands also see better link performance—industry benchmarks show average click-through improvements of 15–20% when recommendations are personalized.
Beyond raw metrics, the real win is reach that’s relevant.
Tools from vendors like Curata, Taboola, and Feedly use behavioral signals, topical intent, and taxonomy-aware tagging to make content discoverable within search, recommendation widgets, and newsletters.
Practical automation—when paired with editorial judgment—turns one-off hits into sustained traffic growth and higher-quality leads.
Improving discoverability: personalized discovery and search relevance
AI moves discovery away from generic topic matching and toward contextual intent.
That means queries and browsing signals inform which content surfaces.
Behavioral signals: AI weights recent reading, clicks, and dwell time to prioritize content that fits individual patterns.
Semantic matching: Advanced models map user intent to articles beyond keyword overlap.
Taxonomy enforcement: Automated tagging keeps metadata consistent so search and internal discovery work reliably.
Cross-channel mapping: The same item can be reformatted for newsletters, widgets, and in-app feeds to widen relevant reach.
Platforms such as Feedly’s Leo and Curata’s recommendation engines demonstrate how signal-driven discovery increases both search relevance and serendipitous discovery.
Boosting engagement: timing, format selection, and audience matching
Better discovery is only half the battle; engagement depends on format and timing.
Right format, right user: AI suggests video, long-form, or listicles based on past engagement patterns.
Time-aware delivery: Scheduling models send recommendations when users are most active.
Segmented messaging: Different audience cohorts receive tailored headlines and previews for higher resonance.
Performance feedback loops: CTR and read-depth feed back into models so recommendations improve continuously.
These practices help explain the 15–20% click-through lift and improved session quality brands see after adopting AI curation.
Operating efficiency: cutting curation time and improving throughput
Operating efficiency: cutting curation time and improving throughput
Metric | Manual curation | AI-driven curation | Expected improvement |
|---|---|---|---|
Time per curated item | 60 minutes (research + vetting) | 42 minutes (automated filtering + quick vetting) | 30% faster |
Personalization depth | Topic-level, rule-based | User-level, behavioral + contextual signals | 70% of consumers prefer tailored recommendations (2025) |
Consistency of tagging | 60–80% taxonomy adherence | 95%+ automated taxonomy enforcement | +20–35 percentage points |
Scalability | Grows linearly with staff (~50 items/day/team) | Automated pipelines; ~300 items/day or more | ~6× throughput |
Operational cost per item | $24–30 per curated item | $8–10 per curated item | ≈60–70% cost reduction |
Those figures reflect industry benchmarks and aggregated case logs.
The table shows where time and cost compress: AI filters noise, applies consistent tags, and surfaces higher-probability items for human review.
That raises throughput without adding headcount.
Pairing these systems with an end-to-end content pipeline — for example, platforms that automate drafting, scheduling, and repurposing — can convert saved hours into clear reach gains. Scaleblogger is one example of a tool that folds curation into a broader publishing workflow.
Small changes in discovery and timing compound quickly.
More relevant reach means each published piece earns more attention and stays useful longer.
Implementation roadmap: from pilot to production
What if the pilot you run this quarter became the engine of your content pipeline next year? Design the pilot so it proves measurable gains in both reach and relevance, then lock in operations that let those gains scale predictably.
Start by defining two to three KPIs that map directly to business outcomes.
Keep one metric for reach (for example, unique referral traffic from curated items) and one for relevance (for example, engagement rate or time-on-article from recommended content).
Use those KPIs to scope a time-boxed pilot with clear success thresholds.
Run the pilot on a narrow slice of traffic and content sources.
That delivers faster feedback and reduces risk.
Measure, iterate, and only then expand the dataset and model scope.
Defining goals: reach and relevance KPIs
Begin with concrete, numeric targets.
Choose a reach KPI such as a 10–20% lift in referral clicks, and a relevance KPI like a 15% higher CTR or a 10% increase in time-on-page.
These numbers align with industry outcomes — brands using AI curation saw average CTR increases of 15–20% and many marketers reported higher engagement in 2025.
Capture baseline values before starting the pilot.
That creates a clean comparison and helps stakeholders accept small early failures while rewarding clear wins.
Pilot design: dataset, A/B tests, guardrails
Design the dataset to mirror production but keep it small.
Select representative sources across formats (articles, video, niche newsletters).
Create two experimental arms: control (human-curated) and treatment (AI-curated).
Implement guardrails: content-safety filters, freshness windows, and a manual override for high-impact channels.
Run an A/B test for at least one business cycle (often 4–6 weeks).
Track both primary KPIs and secondary signals like bounce rate and conversion lift.
Curata, Taboola, and Feedly offer good reference points for source-selection patterns and filtering strategies.
Scaling and governance: retraining cadence, annotation, bias checks
Move from weekly manual tweaks during pilot to an automated retraining cadence in production.
Typical cadence starts at monthly retraining for the first three months, then moves to quarterly once metrics stabilize.
Set up an annotation pipeline with periodic human review and a feedback loop from editorial teams. Include automated bias checks that flag content clusters with skewed sentiment or source concentration.
Pilot-to-production checklist
Pilot-to-production checklist: owners, timeline, success criteria
Activity | Owner | Timeframe | Success criteria |
|---|---|---|---|
Assemble content dataset | Content Lead | 2 weeks | 3,000+ items across 5 source types; freshness <30 days |
Define KPIs and measurement plan | Analytics Lead | 1 week | Baseline captured; target deltas documented |
Select models and tooling | ML Engineer | 2 weeks | Tooling supports A/B and logging; latency <300ms |
Run pilot A/B test | Product Manager | 6 weeks | Statistically significant lift (p<0.05) on 1+ KPI |
Evaluate results and iterate | Data Scientist | 3 weeks | Clear playbook for changes; improvement >10% on target KPI |
Deploy and monitor in production | SRE / Ops | 2 weeks | 99.9% uptime; alerting for KPI regressions |
This checklist reflects practical timelines and owners you can adapt to your org.
Treat the pilot as a living experiment: log decisions, keep the editorial team involved, and bake monitoring into deployment from day one.
If you want reliability, operationalize decisions you proved in the pilot.
A disciplined pilot-to-production path turns initial wins in AI content curation into repeatable growth for content marketing relevance.
Measurement: KPIs, experiments, and attribution
How do you prove that AI-curated recommendations actually changed audience behavior rather than coinciding with it? Measurement for AI content curation must treat the pipeline like a product: define success metrics, run controlled experiments, and accept noisy attribution as part of the landscape.
Start with a concise set of primary KPIs that map directly to business goals: reach, engagement, discovery rate, and retention.
These are the metrics that tell whether curated content is increasing visibility, creating meaningful interaction, surfacing new content to users, and bringing people back over time.
Expect modest tracking gaps at first and plan experiments that measure incremental lift, not just raw numbers.
Remember the industry signal: in 2025, 80% of marketers reported AI-driven content curation improved engagement, and tools like Curata, Taboola, and Feedly are commonly used to operationalize those workflows.
Designing experiments: A/B tests, holdouts, and incremental lift
A clear experiment plan is your best defense against attribution noise.
Run randomized A/B tests when a single change (recommendation algorithm, layout, or headline) is being evaluated.
Holdout groups are essential when new recommendation models roll out across many users simultaneously.
Randomize at the user or session level to avoid contamination between groups.
Define the primary KPI before launching; power the test for incremental lift on that KPI.
Run long enough to capture return visits and seasonal variance—two weeks rarely suffices for retention effects.
Use platform logs, CDN telemetry, and client-side events together to reduce measurement blind spots.
Attribution challenges and practical mitigations
Attribution breaks down because content journeys are multi-touch and cross-device.
Last-click attribution will overcredit one channel and miss assisted conversions from curated feeds.
Event fragmentation: consolidate
content_view,recommendation_impression,recommendation_click,session_start, andconversionevents across platforms.Cross-device identity: prioritize authenticated IDs where possible, and use probabilistic stitching only as backup.
Cookie and tracking loss: mitigate with server-side event collection and hashed identifiers to preserve privacy-compliant continuity.
Experiment design: A/B tests, holdouts, and incremental lift measurement
KPI | Definition | Measurement method | Suggested tracking events |
|---|---|---|---|
Reach | Total unique users exposed to content | Unique user counts from server-side impressions deduplicated by user ID |
|
Click-through rate (CTR) | Percentage of impressions that resulted in clicks | Clicks / impressions per placement; use bootstrap CIs in A/B tests |
|
How long users actively engage with an item | Median and 90th percentile session durations; scrolling and interaction depth |
| |
Content discovery rate | Share of views from new or previously unseen items | Fraction of content views where |
|
Returning viewers / retention | Users who return within a time window (D7, D30) | Cohort retention curves and survival analysis |
|
This table translates KPIs into implementable tracking events you can hand to analytics or engineering teams. Use consistent user_id and item_id schemas to join recommendation telemetry with content metrics.
Testing and attribution are the X-ray for your content pipeline.
Design experiments to measure incremental lift, instrument events consistently, and accept that practical mitigations (server-side collection, authenticated IDs, holdouts) matter more than perfect models.
When measurement is treated like product development, AI content curation stops being a black box and becomes a repeatable growth lever.
📥 Download: Download Template (PDF)
Risks, limitations, and ethical considerations
AI-driven curation can significantly enhance efficiency and engagement in content marketing, but it also introduces ethical challenges and responsibilities.
While many organizations report increased engagement and consumer preference for tailored recommendations, the technology must be monitored to prevent bias and ensure content quality.
Effective governance mechanisms are essential to mitigate these risks, allowing teams to capitalize on the benefits of AI while maintaining accountability and transparency in their curation processes.
📥 Download: Download Template (PDF)
Conclusion
Turn content noise into predictable relevance
Imagine turning the endless scroll into a steady signal that points to what your audience actually wants. AI-driven content curation does precisely that: it ingests trending pieces, audience behavior, and topic clusters, then surfaces ideas that make content marketing relevance repeatable rather than accidental.
That change—from overwhelmed creators chasing every trend to a reproducible discovery process—was the throughline in the roadmap and measurement sections.
You don’t need to overhaul your stack to start seeing results. Run a two-week pilot that uses AI for content discovery to generate 10 article ideas, map each to a single KPI (CTR, time on page, or a micro-conversion), and A/B test the top 3.
Measure uplift, iterate on the signals that worked, and scale the pipeline into production; tools like ScaleBlogger can automate much of that flow if you want to move faster.
Do this and you’ll stop guessing and start prioritizing stories that actually resonate.
Which one audience question will you turn into a focused, data-driven piece this week?
